[자료구조 2] 해시테이블(HashTable) 이해하기
(Key, Value) 형태를 가진 데이터를 효율적으로 저장하고 빠르게 찾기 위해 해시테이블(HashTable)을 사용할 수 있습니다. 이 포스팅에서는 해시테이블이 무엇이고 어떻게 구현하는지를 예제를 통해 알아봅니다.
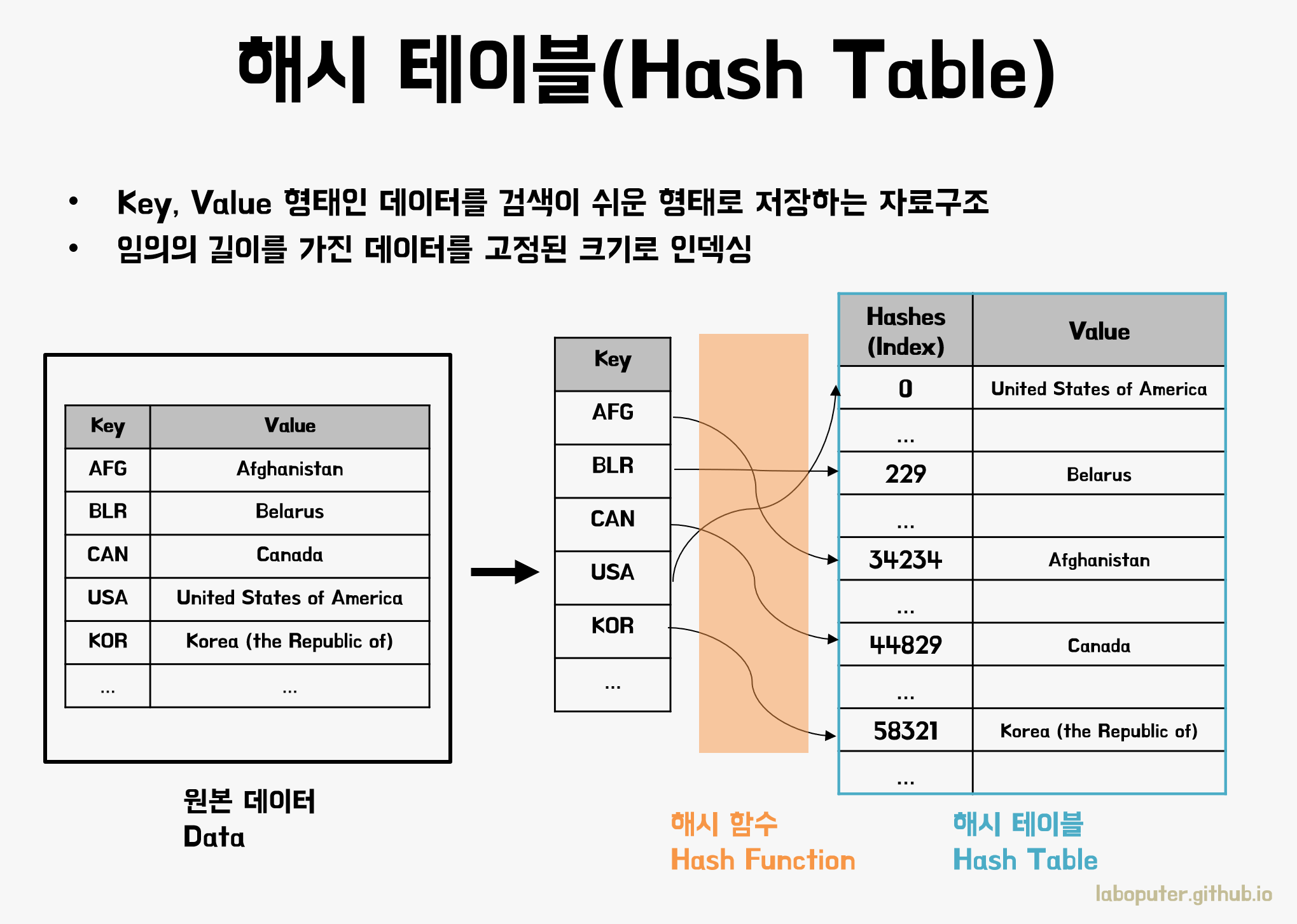
해시테이블(HashTable)
해시테이블은 (Key, Value) 데이터를 아주 빠르게 찾아낼 수 있는 자료구조입니다. 배열이 인덱스 번호로 O(1)만에 해당 위치의 값을 찾아낼 수 있는 것처럼 매우 큰 숫자 데이터나 문자열과 같이 임의의 길이를 가진 Key값을 고정된 작은 값으로 매핑하여 O(1)에 가까운 빠른속도로 찾을 수 있습니다.
시간복잡도
위 그림처럼 국가코드(Key)가 주어지면 국가명(Value)을 찾는다고 합시다. 배열로 저장해놓게 되면 모든 국가(N개)의 Key값을 비교해야 하므로 시간복잡도는 O(N)이지만, 해시함수를 이용하여 Key에 해당하는 해시값만 계산하면 O(1)만에 찾을 수 있게 됩니다.
물론 Key값의 길이나 해시테이블의 크기를 얼마나 잡느냐에 따라 정확한 시간복잡도 계산은 다르지만, 해시테이블은 매우 빠릅니다.
그럼 해시값을 만들어주는 해시함수는 어떻게 만들까요?
해시 함수(Hash Function), 해시 충돌(Hash Collision)

해시 함수
해시 함수는 모든 입력에 대해 일정한 값 이하로 만들어주기만 하면 됩니다. 이것은 매우 쉽습니다.
Key값이 문자열이라고 할 때 아래와 같은 코드를 보면
char* str = "example"
int hash = 0
for (int i=0; i<len(str); i++)
hash = ((hash + str[i]) * 31) % K
첫번째 문자는 31^5를 곱하고 두번째는 31^4를 곱하는 식으로 반복한 값들을 모두 더한 후 K로 나눈 나머지값을 구하면 K값 이하인 인덱스로 매핑할 수 있습니다.
해시값 구하는 방식도, K 상수값은 몇으로 할지는 자유입니다. 여기서 해시테이블의 메모리 크기는 K개면 저장할 수 있습니다. 한가지 문제가 발생하지만요.
여기서 문제는 서로 다른 문자열인데 우연히 해시값이 같을 수도 있습니다. 이것을 해시 충돌(Hash Collision)이라고 합니다.
해시 충돌
우리는 해시 충돌이 최대한 적게 일어나서 그리고 각 인덱스마다 데이터가 최대한 고르게 퍼지도록 해시함수를 만들어주어야 합니다. 어느 한쪽의 인덱스에 해시값이 쏠리게 되면 그냥 일반적인 배열을 탐색하는 것과 같아지기 때문입니다.
하지만 해시 충돌이 절대로 없게 만들수는 없지만, 충분히 고르게 해시값을 생성할 수 있습니다. 대신에 충돌이 나더라도 같은 해시값을 가진 여러 개의 입력값을 넣을 수 있도록 해시테이블을 구현해야 합니다.
이러한 구현 방법은 여러가지가 있지만 한가지만 소개합니다.
List hashtable[K];
위처럼 단순히 각 해시값마다 리스트로 만들고 다른 Key값이지만 같은 해시값이 나오면 List에 추가해주기만 하면 됩니다. 이를 체이닝(Chaining)이라고 합니다.
K 값을 결정하는 것은 정해진 방법은 없지만 개인적으로는 아래와 같이 사용합니다.
- K가 소수일 것
- K는 2의 지수승에 가까울 것
- K의 크기는 전체 데이터의 수의 3배 정도
예제: 비밀번호 찾기
문제 링크:: 비밀번호 찾기(https://www.acmicpc.net/problem/17219)
자세한 문제 설명은 위 링크로 들어가셔서 확인하시고 직접 풀어보세요!
아이디(Key), 패스워드(Value) 쌍으로된 문자열 데이터가 주어지고, 아이디가 주어지면 패스워드를 찾아내는 문제입니다.
풀이
문제 제약조건을 보고 최악의 경우를 생각해보면 10만개의 20글자인 아이디/패스워드가 주어지고 아이디 10만개가 모두 주어지는 경우입니다. 일반적인 배열을 체크하는 것으로는 풀수 없음을 알 수 있습니다.
이 문제는 해시테이블을 구성하여 Key가 주어졌을 때 Value를 효율적으로 탐색할 수 있으면 쉽게 풀 수 있습니다.
전체 코드:
#include <stdio.h>
#include <vector>
using namespace std;
int N, M;
char key[100005][21];
char value[100005][21];
#define H 582717
vector<int> hashtable[H];
int Hash(char* str)
{
long long hash = 37;
for (int i = 0; str[i]; i++)
hash = ((hash + str[i]) * 31) % (long long)H;
return hash;
}
char* FindKey(char* query)
{
int hash = Hash(query);
for (vector<int>::iterator start = hashtable[hash].begin(); start != hashtable[hash].end(); start++)
{
bool same = 1;
for (int i = 0; query[i] != 0 || key[*start][i] != 0; i++)
if (query[i] != key[*start][i])
same = 0;
if (same) return value[*start];
}
return 0;
}
int main()
{
scanf("%d%d", &N, &M);
for (int i = 0; i < N; i++)
{
scanf("%s %s\n", key[i], value[i]);
hashtable[Hash(key[i])].push_back(i);
}
char query[25];
for (int i = 0; i < M; i++)
{
scanf("%s", query);
printf("%s\n", FindKey(query));
}
}
Key, Value를 처리할 수 있도록 이미 구현되어 있는 C++ 의 map<>을 사용할수 있습니다.
map<>을 사용한 코드:
#include <stdio.h>
#include <map>
#include <string>
using namespace std;
int N, M;
map<string, string> strmap;
int main()
{
scanf("%d%d", &N, &M);
char key[25], value[25];
for (int i = 0; i < N; i++)
{
scanf("%s %s\n", key, value);
strmap[string(key)] = string(value);
}
char query[25];
for (int i = 0; i < M; i++)
{
scanf("%s", query);
printf("%s\n", strmap[string(query)].c_str());
}
}
다른 문제 추천
- 나는야 포켓몬 마스터 이다솜: (https://www.acmicpc.net/problem/1620)
- 암기왕: (https://www.acmicpc.net/problem/2776)
해시테이블은 개념 자체가 알고리즘을 이해하는데 있어서 중요하다고 판단해서 직접 구현해봤습니다. 방법을 이미 아신다면 Key, Value 데이터를 다룰 수 있는 C++의 Map, Python의 Dictionary 같이 일반적인 STL을 사용하시면 됩니다.