MNIST 숫자 분류, 기본 모델부터 정확도 99.5% 까지
in Machine Learning on 예제로 이해하는 이론, Tutorial
텐서플로우(Tensorflow 2.0) 기반으로 여러가지 예측모델을 구현하면서 MNIST 숫자 이미지 분류를 정답률 99.5% 까지 달성하기까지의 과정을 포스팅합니다.
기본적인 로지스틱 회귀(Logistic regression)부터 이미지 인식에 좋은 성능을 보이는 컨볼루션 뉴럴 네트워크(CNN) 까지 구현해봅니다. 단계별로 정답률을 올려보면서 머신러닝 이론들을 이해해보는 것을 목표로 합니다.
MNIST 손글씨 이미지 문제
MNIST 손글씨 이미지 문제는 0~9 까지의 숫자를 사람이 손글씨로 작성한 이미지로부터 어떤 숫자인지 분류하는 것입니다. 대표적인 Classification 문제에 대한 머신러닝 튜토리얼로 많이 활용되는 데이터셋입니다.
MNIST 데이터셋 설명:
- 0~255 사이의 값을 가진 28x28 흑백이미지와 실제 숫자값에 해당하는 데이터세트가 총 7만개가 주어집니다.
- 6만개는 학습용, 1만개는 테스트용으로 주어집니다.
여기서 학습용 데이터는 예측모델을 학습하는 용도로 사용하고 테스트용 데이터는 학습에 사용되지 않고 새로운 값에 대해 어느정도로 예측하는지 검증하는 용도로 사용합니다.
1. MNIST 다운로드 및 데이터 확인하기
텐서플로우에서 MNIST 데이터를 다운로드 받습니다.
import tensorflow as tf
(x_train, y_train), (x_test, y_test) = tf.keras.datasets.mnist.load_data()
다운로드 받은 데이터를 shape를 통해 확인해보면 6만개의 28x28 이미지와 실제 숫자(정답)가 있습니다.
print(x_train.shape) # (60000, 28, 28)
print(y_train.shape) # (60000, )
첫번째 데이터가 실제 어떤 이미지를 가지는지 matplotlib을 이용하여 시각화할 수 있습니다.
import matplotlib.pyplot as plt
print("Y[0] : ", y_train[0])
plt.imshow(x_train[0], cmap=plt.cm.gray_r, interpolation = "nearest")
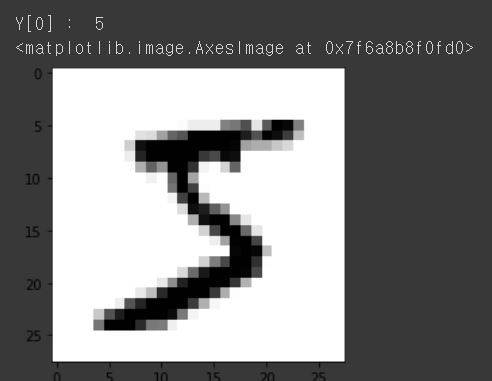
결과를 보는 것처럼 5가 정답이며 이미지를 시각화하면 실제 5로 보이는 것을 확인하실 수 있습니다.
2. 로지스틱 회귀, 통계적인 방법으로 접근하기
로지스틱 회귀(Logistic regression)를 이용하여 이미지 데이터를 총 784개(28 x 28)를 독립변수로 가정하고 숫자를 0~9 까지 분류하도록 학습모델을 만듭니다.
데이터 전처리
학습을 하기 전에는 항상 데이터를 학습하기 좋은 형태로 전처리를 해야 합니다. 대표적으로 0~1 사이의 값으로 Normalization을 진행합니다. Feature 간에 스케일 조정 그리고 학습속도에 영향을 줍니다. 이 예제에서 Normalization 진행 여부에 따라 예측률이 87% 에서 92% 로 올라갑니다. 아마도 예제코드가 learning rate가 낮기 때문으로 보입니다.
x_train, x_test = x_train / 255.0, x_test / 255.0
one-hot 인코딩은 카테고리를 표현할 때 자주 사용하는 방법으로 카테고리를 표현할 때 X 가 아닌 1차원 array 형태(ex: 0, 1, 2 카테고리에서 1은 [0, 1, 0])로 나타냅니다. 텐서플로우에서 to_categorical()을 이용합니다.
y_train = tf.keras.utils.to_categorical(y_train, 10)
y_test = tf.keras.utils.to_categorical(y_test, 10)
예측모델 생성 및 학습
Dense 레이어를 통해 784개의 입력과 10개의 출력을 만들고 softmax로 카테고리 별 확률값(총합은 1)으로 output이 나오도록 합니다. loss function은 categorical_crossentropy를 이용하고, optimizer는 Adam을 이용하였습니다. 실제로 데이터 학습은 fit 함수를 통해 이루어지고 validation_data를 통해서 학습 과정에 테스트용 데이터로 예측률을 계산하여 과정을 출력할 수 있습니다.
model = tf.keras.Sequential()
model.add(tf.keras.layers.Dense(units=10, input_dim=784, activation='softmax'))
model.compile(loss='categorical_crossentropy', optimizer=tf.optimizers.Adam(lr=0.001), metrics=['accuracy'])
model.summary()
model.fit(x_train, y_train, batch_size=100, epochs=10, validation_data=(x_test, y_test))
# _________________________________________________________________
# Layer (type) Output Shape Param #
# =================================================================
# dense_32 (Dense) (None, 10) 7850
# =================================================================
# Total params: 7,850
# Trainable params: 7,850
# Non-trainable params: 0
# _________________________________________________________________
# Epoch 6/10
# 600/600 [==============================] - 1s 2ms/step - loss: 0.2745 - accuracy: 0.9234 - val_loss: 0.2739 - val_accuracy: 0.9229
# Epoch 7/10
# 600/600 [==============================] - 1s 2ms/step - loss: 0.2697 - accuracy: 0.9251 - val_loss: 0.2693 - val_accuracy: 0.9245
# Epoch 8/10
# 600/600 [==============================] - 1s 2ms/step - loss: 0.2651 - accuracy: 0.9263 - val_loss: 0.2684 - val_accuracy: 0.9235
# Epoch 9/10
# 600/600 [==============================] - 1s 2ms/step - loss: 0.2622 - accuracy: 0.9269 - val_loss: 0.2657 - val_accuracy: 0.9268
# Epoch 10/10
# 600/600 [==============================] - 1s 2ms/step - loss: 0.2589 - accuracy: 0.9277 - val_loss: 0.2661 - val_accuracy: 0.9255
# 313/313 [==============================] - 1s 2ms/step - loss: 0.2658 - accuracy: 0.9255
# 최종 예측 성공률(%): 92.5499975681305
학습 결과 (로지스틱 회귀)
학습된 모델은 새로운 숫자이미지에 대해 92% 예측률을 보입니다.
이 간단한 코드로도 숫자이미지를 10개중 9개를 정확히 분류할 수 있는 대단한 예측모델이 만들어졌습니다. 하나의 픽셀을 단순히 변수로 가정하고 회귀모델을 구성하여도 꽤 괜찮은 학습결과가 나타납니다.
3. 뉴럴 네트워크(Neural Network)
2번 과정에서 단순히 학습모델만 변경할 것 입니다. 사실은 2번 모델에서처럼 하나의 레이어로는 XOR 문제도 분류해내지 못합니다. 레이어를 여러층을 두는 딥러닝(Deeplearning)으로 시도해봅니다. 데이터 전처리나 모든 파라미터들은 동일하고 학습모델만 변경합니다.
Dense 레이어를 add 해주기만 하면 손쉽게 레이어를 여러개 둘 수 있습니다. 이때 딥러닝 학습과정에서 activation을 sigmoid로 진행할 경우 vanishing gradient 문제가 발생하기 때문에 보통 relu를 많이 이용합니다.
학습 모델:
model = tf.keras.Sequential()
model.add(tf.keras.layers.Dense(units=256, input_dim=784, activation='relu'))
model.add(tf.keras.layers.Dense(units=128, activation='relu'))
model.add(tf.keras.layers.Dense(units=64, activation='relu'))
model.add(tf.keras.layers.Dense(units=32, activation='relu'))
model.add(tf.keras.layers.Dense(units=10, activation='softmax'))
model.compile(loss='categorical_crossentropy', optimizer=tf.optimizers.Adam(lr=0.001), metrics=['accuracy'])
model.summary()
model.fit(x_train, y_train, batch_size=100, epochs=10, validation_data=(x_test, y_test))
# _________________________________________________________________
# Layer (type) Output Shape Param #
# =================================================================
# dense_33 (Dense) (None, 256) 200960
# _________________________________________________________________
# dense_34 (Dense) (None, 128) 32896
# _________________________________________________________________
# dense_35 (Dense) (None, 64) 8256
# _________________________________________________________________
# dense_36 (Dense) (None, 32) 2080
# _________________________________________________________________
# dense_37 (Dense) (None, 10) 330
# =================================================================
# Total params: 244,522
# Trainable params: 244,522
# Non-trainable params: 0
# _________________________________________________________________
# Epoch 6/10
# 600/600 [==============================] - 1s 2ms/step - loss: 0.0356 - accuracy: 0.9887 - val_loss: 0.0813 - val_accuracy: 0.9759
# Epoch 7/10
# 600/600 [==============================] - 1s 2ms/step - loss: 0.0290 - accuracy: 0.9905 - val_loss: 0.0687 - val_accuracy: 0.9785
# Epoch 8/10
# 600/600 [==============================] - 1s 2ms/step - loss: 0.0236 - accuracy: 0.9923 - val_loss: 0.0906 - val_accuracy: 0.9759
# Epoch 9/10
# 600/600 [==============================] - 1s 2ms/step - loss: 0.0211 - accuracy: 0.9931 - val_loss: 0.0767 - val_accuracy: 0.9796
# Epoch 10/10
# 600/600 [==============================] - 1s 2ms/step - loss: 0.0194 - accuracy: 0.9934 - val_loss: 0.0922 - val_accuracy: 0.9766
# 313/313 [==============================] - 1s 2ms/step - loss: 0.0920 - accuracy: 0.9766
# 최종 예측 성공률(%): 97.65999913215637
학습결과 (뉴럴네트워크)
딥 뉴럴 네트워크로 학습된 모델은 97% 예측률을 보입니다.
2번 과정에서 모델만 변경하시면 같은 결과를 얻으실 수 있습니다. 이처럼 레이어를 여러층 두는 딥네트워크를 구성하는 것만으로도 학습 효과가 좋음을 알 수 있었습니다.
4. 컨볼루션 뉴럴 네트워크(CNN)
영상처리에서 사용하는 컨볼루션이라는 연산이 있습니다. 3번과 동일하게 딥 네트워크를 구성하지만 컨볼루션 연산을 통과한 새로운 이미지는 이미지의 경계선을 뽑거나 흐리게 만들거나 하는 등 다양한 특징을 뽑아낼 수 있습니다. 학습 네트워크 상에서 이 컨볼루션 연산을 어떻게 해야되는지 또한 학습을 통해 찾게 됩니다. 이러한 구성을 가진 CNN은 영상인식에서 뛰어난 성능을 보입니다. 특히 딥러닝이 가장 강력하게 힘을 발휘하는 곳이 영상인식 분야이기도 합니다.
Conv2d()를 이용하여 컨볼루션 레이어를 만들 수 있습니다. 이것은 특징을 뽑아주는 용도로 생각하면 됩니다.
- kernel_size : 컨볼루션 연산을 할 크기(행,열)
- filters : 필터 이미지 개수
- padding : 경계처리 방법 (same은 출력사이즈가 입력사이즈와 동일하게 합니다)
tf.keras.layers.Conv2D(kernel_size=(3,3), filters=128, padding='same', activation='relu')
MaxPooling2D()를 이용하여 맥스풀링 레이어를 만듭니다. 이것은 이미지의 작은 부분을 무시하기 위해 사용하고 학습할 파라미터의 양도 줄일 수 있습니다.
- pool_size : 맥스풀링할 크기(행,열)
tf.keras.layers.MaxPooling2D(pool_size=(2, 2))
Flatten()을 이용하여 Fully Connected 레이어를 만듭니다. 이것은 다차원의 입력을 단순히 일차원으로 만들기 위해 사용했습니다.
tf.keras.layers.Flatten()
그리고 기존에는 없던 Dropout() 레이어도 추가합니다. Overfitting을 방지하기 위해서 사용하였습니다.
- rate: dropout할 비율(1이면 100%)
tf.keras.layers.Dropout(rate=0.5)
MNIST를 학습하는 모델을 컨볼루션으로 특징을 추출하고 이를 다시 일차원으로 변경시켜 딥 네트워크로 구성하여 학습하도록 진행하였습니다.
전체 코드:
import tensorflow as tf
import numpy as np
import matplotlib.pyplot as plt
(x_train, y_train), (x_test, y_test) = tf.keras.datasets.mnist.load_data()
# 각종 파라메터의 영향을 보기 위해 랜덤값 고정
tf.random.set_seed(1234)
# Normalizing data
x_train, x_test = x_train / 255.0, x_test / 255.0
# (60000, 28, 28) => (60000, 28, 28, 1)로 reshape
x_train = x_train.reshape(-1, 28, 28, 1)
x_test = x_test.reshape(-1, 28, 28, 1)
# One-hot 인코딩
y_train = tf.keras.utils.to_categorical(y_train, 10)
y_test = tf.keras.utils.to_categorical(y_test, 10)
model = tf.keras.Sequential([
tf.keras.layers.Conv2D(kernel_size=(3,3), filters=64, input_shape=(28,28,1), padding='same', activation='relu'),
tf.keras.layers.Conv2D(kernel_size=(3,3), filters=64, padding='same', activation='relu'),
tf.keras.layers.MaxPool2D(pool_size=(2,2)),
tf.keras.layers.Conv2D(kernel_size=(3,3), filters=128, padding='same', activation='relu'),
tf.keras.layers.Conv2D(kernel_size=(3,3), filters=256, padding='valid', activation='relu'),
tf.keras.layers.MaxPool2D(pool_size=(2,2)),
tf.keras.layers.Flatten(),
tf.keras.layers.Dense(units=512, activation='relu'),
tf.keras.layers.Dropout(0.5),
tf.keras.layers.Dense(units=256, activation='relu'),
tf.keras.layers.Dropout(0.5),
tf.keras.layers.Dense(units=10, activation='softmax')
])
model.compile(loss='categorical_crossentropy', optimizer=tf.optimizers.Adam(lr=0.001), metrics=['accuracy'])
model.summary()
model.fit(x_train, y_train, batch_size=100, epochs=10, validation_data=(x_test, y_test))
result = model.evaluate(x_test, y_test)
print("최종 예측 성공률(%): ", result[1]*100)
# _________________________________________________________________
# Layer (type) Output Shape Param #
# =================================================================
# conv2d_16 (Conv2D) (None, 28, 28, 64) 640
# _________________________________________________________________
# conv2d_17 (Conv2D) (None, 28, 28, 64) 36928
# _________________________________________________________________
# max_pooling2d_8 (MaxPooling2 (None, 14, 14, 64) 0
# _________________________________________________________________
# conv2d_18 (Conv2D) (None, 14, 14, 128) 73856
# _________________________________________________________________
# conv2d_19 (Conv2D) (None, 12, 12, 256) 295168
# _________________________________________________________________
# max_pooling2d_9 (MaxPooling2 (None, 6, 6, 256) 0
# _________________________________________________________________
# flatten_4 (Flatten) (None, 9216) 0
# _________________________________________________________________
# dense_12 (Dense) (None, 512) 4719104
# _________________________________________________________________
# dropout_2 (Dropout) (None, 512) 0
# _________________________________________________________________
# dense_13 (Dense) (None, 256) 131328
# _________________________________________________________________
# dropout_3 (Dropout) (None, 256) 0
# _________________________________________________________________
# dense_14 (Dense) (None, 10) 2570
# =================================================================
# Total params: 5,259,594
# Trainable params: 5,259,594
# Non-trainable params: 0
# _________________________________________________________________
# Epoch 6/10
# 600/600 [==============================] - 22s 37ms/step - loss: 0.0230 - accuracy: 0.9939 - val_loss: 0.0222 - val_accuracy: 0.9935
# Epoch 7/10
# 600/600 [==============================] - 22s 37ms/step - loss: 0.0208 - accuracy: 0.9943 - val_loss: 0.0229 - val_accuracy: 0.9933
# Epoch 8/10
# 600/600 [==============================] - 22s 37ms/step - loss: 0.0178 - accuracy: 0.9947 - val_loss: 0.0232 - val_accuracy: 0.9943
# Epoch 9/10
# 600/600 [==============================] - 22s 37ms/step - loss: 0.0150 - accuracy: 0.9955 - val_loss: 0.0377 - val_accuracy: 0.9897
# Epoch 10/10
# 600/600 [==============================] - 22s 37ms/step - loss: 0.0151 - accuracy: 0.9958 - val_loss: 0.0217 - val_accuracy: 0.9950
# 313/313 [==============================] - 2s 7ms/step - loss: 0.0216 - accuracy: 0.9950
# 최종 예측 성공률(%): 99.50000047683716
학습 결과(컨볼루션 뉴럴네트워크)
드디어 새로운 이미지에 대해 99.5%로 숫자를 분류해내는 모델을 만들었습니다. 이것처럼 CNN을 이용한 딥러닝 네트워크는 이미지 인식에서 뛰어난 성능을 보임을 알 수 있습니다.
MNIST SOTA(State Of The Art)에 따르면 2020년 기준 최고 성능이 99.84% 으로 공개되어 있습니다. 이에 비하면 간단한 모델로도 충분히 좋은 성능을 내는 것을 확인하실 수 있습니다.
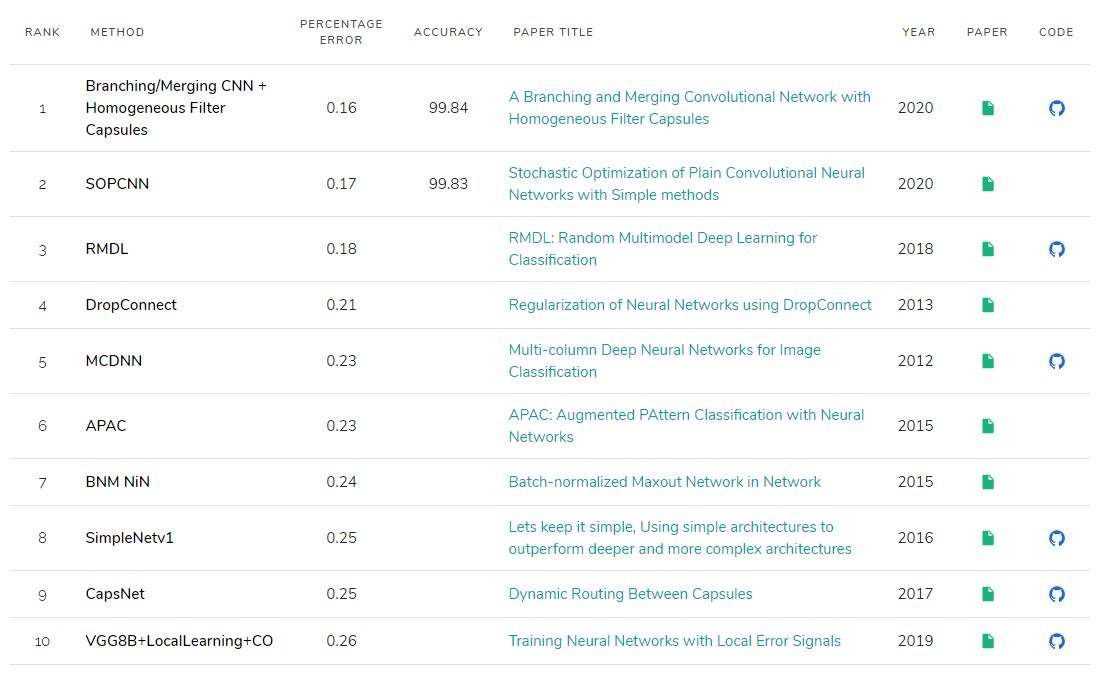
비슷한 구조로 레이어를 추가/삭제 또는 learning_rate, batch_size 등 다양한 파라미터를 변경하거나 같은 모델을 여러개 사용하여 종합 평가를 하는 앙상블(ensemble) 학습도 시도해보면 더 높은 정확도를 만드실 수 있습니다. 이를 보통 ‘모델을 튜닝한다.’ 라고 표현을 하는데 실제로 변경해보면서 여러 가지 시도를 하시면 더 많은 것을 얻어가실 수 있을 것 같습니다. SOTA에 공개된 코드를 시도해보셔도 좋은 공부가 될 것 같습니다.
이 포스팅에서 사용한 코드는 이곳에 공개되어 있으며 다운로드 받으실 수 있습니다.