판다스(Pandas) 사용법 알아보기
in Machine Learning on Python, Tutorial, Pandas
판다스 공식홈페이지 10 minutes to pandas에서 소개된 기본적인 사용법을 따라하면서 번역한 글입니다. 직역하기 보다는 간단하게 요약하고 설명이 더 필요한 부분은 추가하였으니 도움되시길 바랍니다.
이 글을 읽으신 후에 더 자세한 내용이 필요하시면 아래 링크를 확인해보세요.
- 공식 홈페이지
- Documentation
- Tutorial
- 10 minutes to pandas (이 글에서 소개된 내용)
- Cookbook
목차
포스팅 하나로 정리하다보니 내용이 많아 원하는 챕터만 링크 클릭하셔서 보셔도 됩니다.
- 오브젝트 생성 (Object Creation)
- 데이터 확인하기 (Viewing Data)
- 데이터 선택하기 (Selection)
- 결측 데이터 (Missing Data)
- 데이터 연산 (Operations)
- 데이터 합치기 (Merge)
- 그룹화 (Grouping)
- 데이터 구조 변경하기 (Reshaping)
- 시계열 데이터 (Time Series)
- 범주형 데이터 (Categoricals)
- 그래프 시각화 (Plotting
- 파일 입출력 (Getting Data In/Out)
Pandas
판다스(Pandas)는 Python에서 DB처럼 테이블 형식의 데이터를 쉽게 처리할 수 있는 라이브러리 입니다. 데이터가 테이블 형식(DB Table, csv 등)으로 이루어진 경우가 많아 데이터 분석 시 자주 사용하게 될 Python 패키지입니다.
이 글에서는 아래와 같이 3가지 패키지가 활용됩니다.
패키지가 없으신 경우, 설치 명령어: pip install pandas
import pandas as pd
import numpy as np
# 시각화 패키지
import matplotlib.pyplot as plt
%matplotlib inline
1. 오브젝트 생성 (Object Creation)
판다스(Pandas)에서 사용하는 기본적인 오브젝트(Object)를 생성하는 방법에 대해 소개합니다.
이 장에 대해 자세한 설명은 Data Structure Intro section를 참고하세요.
생성하는 방법을 알기 전에 판다스에서 사용하는 기본적인 오브젝트(Object)란 무엇일까요?

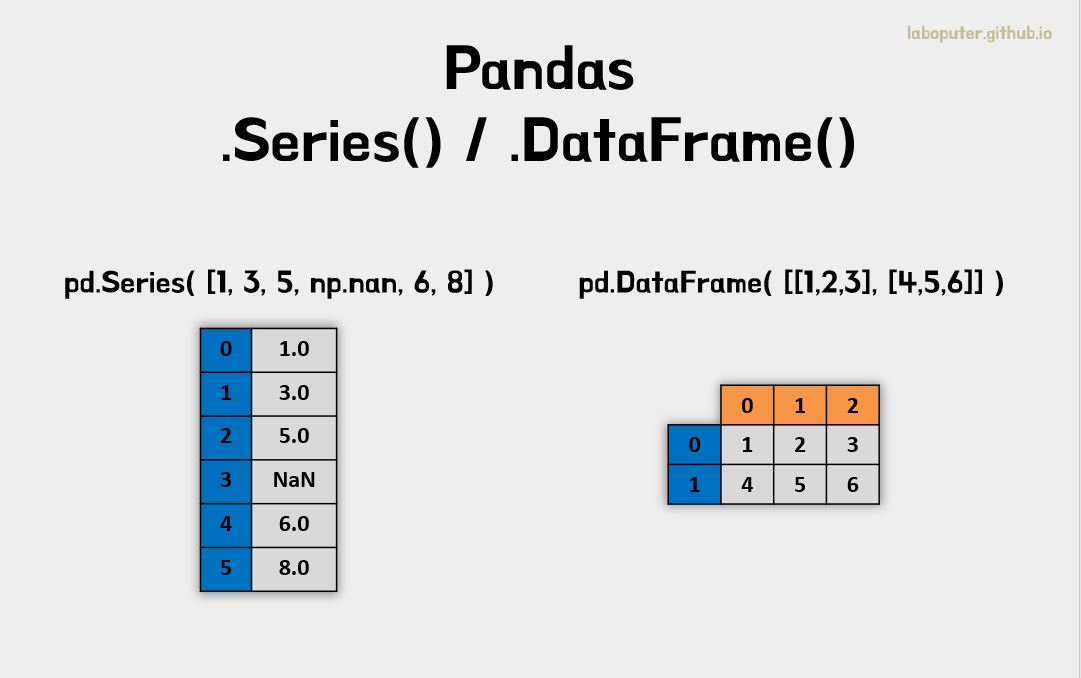
위 그림처럼 판다스에서는 2가지 오브젝트 Series 와 DataFrame가 있습니다.
Series: 1차원 데이터와 각 데이터의 위치정보를 담는 인덱스로 구성DataFrame: 2차원 데이터와 인덱스, 컬럼으로 구성
쉽게 생각하면 DataFrame에서 하나의 컬럼만 가지고 있는 것이 Series입니다.
Series는 어떻게 생성할 수 있을까요?
s = pd.Series([1,3,5,np.nan,6,8])
# 0 1.0
# 1 3.0
# 2 5.0
# 3 NaN
# 4 6.0
# 5 8.0
# dtype: float64
위와 같이 Series() 안에 list로 1차원 데이터만 넘기면 됩니다. index는 입력하지 않아도 자동으로 0부터 입력됩니다. 만약 다른 index를 입력하고 싶으시면 똑같이 list 형식으로 입력하면 됩니다.
DataFrame은 어떻게 생성할까요?
dates = pd.date_range('20130101', periods=6)
# DatetimeIndex(['2013-01-01', '2013-01-02', '2013-01-03', '2013-01-04',
# '2013-01-05', '2013-01-06'],
# dtype='datetime64[ns]', freq='D')
df = pd.DataFrame(np.random.randn(6,4), index=dates, columns=list('ABCD'))
# A B C D
# 2013-01-01 1.571507 0.160021 -0.015071 -0.118588
# 2013-01-02 -1.037697 -0.891196 0.495447 0.453095
# 2013-01-03 -1.682384 -0.026006 -0.152957 -0.212614
# 2013-01-04 -0.108757 -0.958267 0.407331 0.187037
# 2013-01-05 1.092380 2.841777 -0.125714 -0.760722
# 2013-01-06 1.638509 -0.601126 -1.043931 -1.330950
먼저 index가 시간에 관련된 데이터라고 가정하고 data_range()를 이용하여 시간에 대한 1차원 데이터를 생성하였습니다. 그리고 np.random.randn()을 통해 6x4에 해당하는 2차원 데이터를 생성하였습니다. columns 또한 DataFrame에서 사용될 컬럼의 이름을 1차원 데이터(A,B,C,D)로 생성합니다. 위 3가지 데이터 (컬럼, 인덱스, 2차원 데이터)를 가지고 만들었습니다.
자주 사용하는 딕셔너리 형식으로도 DataFrame을 만들 수 있습니다.
df2 = pd.DataFrame({'A':1.,
'B':pd.Timestamp('20130102'),
'C':pd.Series(1,index=list(range(4)),dtype='float32'),
'D':np.array([3]*4,dtype='int32'),
'E':pd.Categorical(["test","train","test","train"]),
'F':'foo'})
# A B C D E F
# 0 1.0 2013-01-02 1.0 3 test foo
# 1 1.0 2013-01-02 1.0 3 train foo
# 2 1.0 2013-01-02 1.0 3 test foo
# 3 1.0 2013-01-02 1.0 3 train foo
각 Key값과 Value(1차원 데이터)가 DataFrame의 하나의 컬럼과 2차원 데이터가 됩니다. 당연하겠지만 모든 딕셔너리의 Value의 리스트 길이가 같아야 생성할 수 있습니다.
DataFrame의 .dtypes라는 값에는 각 컬럼이 어떤 데이터 형식인지가 저장되어 있습니다. 만약 섞여있을 경우 object가 됩니다.
df2.dtypes
# A float64
# B datetime64[ns]
# C float32
# D int32
# E category
# F object
# dtype: object
.dtypes외의 다른 속성값을 보고 싶은 경우,
- Jupyter Notebook: df. 입력후 TAB 입력
- Visual Studio Code: df. 입력후 CTRL + SPACE 입력
df2.<TAB>
# df2.A df2.bool
# df2.abs df2.boxplot
# df2.add df2.C
# df2.add_prefix df2.clip
# df2.add_suffix df2.clip_lower
# df2.align df2.clip_upper
# df2.all df2.columns
# df2.any df2.combine
# df2.append df2.combine_first
# df2.apply df2.consolidate
# df2.applymap
# df2.D
각 컬럼의 이름이 속성값으로 Series가 들어가 있는 것을 확인할 수 있습니다.
# df2의 'A' 컬럼 값을 보여줍니다.
df2.A
# 0 1.0
# 1 1.0
# 2 1.0
# 3 1.0
# Name: A, dtype: float64
2. 데이터 확인하기 (Viewing Data)
이 장에 대해 자세한 설명은 Basics section을 확인하세요.
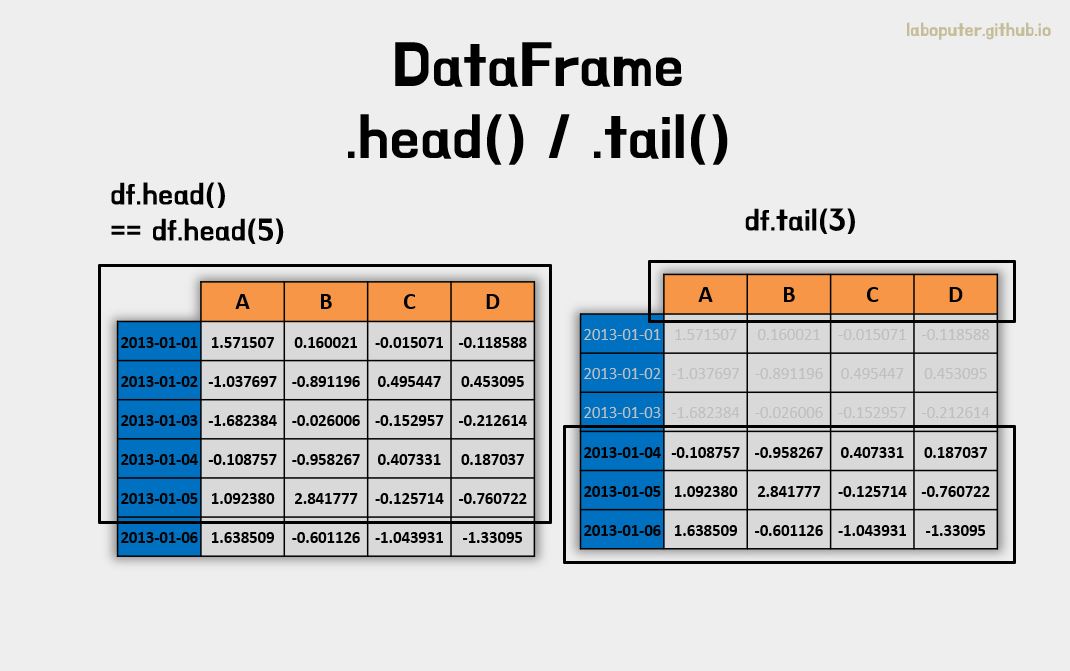
DataFrame은 head(), tail()의 함수로 처음과 끝의 일부 데이터만 살짝 볼 수 있습니다. 데이터가 큰 경우에 데이터가 어떤식으로 구성되어 있는지 확인할 때 자주 사용합니다.
# 첫번째 행부터 5개(기본값)를 보여줍니다.
df.head()
# A B C D
# 2013-01-01 1.571507 0.160021 -0.015071 -0.118588
# 2013-01-02 -1.037697 -0.891196 0.495447 0.453095
# 2013-01-03 -1.682384 -0.026006 -0.152957 -0.212614
# 2013-01-04 -0.108757 -0.958267 0.407331 0.187037
# 2013-01-05 1.092380 2.841777 -0.125714 -0.760722
# 마지막 행에서 3개를 보여줍니다.
df.tail(3)
# A B C D
# 2013-01-04 -0.108757 -0.958267 0.407331 0.187037
# 2013-01-05 1.092380 2.841777 -0.125714 -0.760722
# 2013-01-06 1.638509 -0.601126 -1.043931 -1.330950
DataFrame의 대표적인 값인 .columns, .index, .values는 다음과 같이 각각 확인할 수 있습니다.
df.index
# DatetimeIndex(['2013-01-01', '2013-01-02', '2013-01-03', '2013-01-04',
# '2013-01-05', '2013-01-06'],
# dtype='datetime64[ns]', freq='D')
df.columns
# Index(['A', 'B', 'C', 'D'], dtype='object')
df.values
# [[ 1.571507 0.160021 -0.015071 -0.118588]
# [-1.037697 -0.891196 0.495447 0.453095]
# [-1.682384 -0.026006 -0.152957 -0.212614]
# [-0.108757 -0.958267 0.407331 0.187037]
# [ 1.09238 2.841777 -0.125714 -0.760722]
# [ 1.638509 -0.601126 -1.043931 -1.33095 ]]

DataFrame의 to_numpy()를 이용하여 인덱스와 컬럼을 제외한 2차원 데이터만을 numpy의 형식으로 반환해줍니다. 사실은 .values와 동일합니다.
df.to_numpy()
# [[ 1.571507 0.160021 -0.015071 -0.118588]
# [-1.037697 -0.891196 0.495447 0.453095]
# [-1.682384 -0.026006 -0.152957 -0.212614]
# [-0.108757 -0.958267 0.407331 0.187037]
# [ 1.09238 2.841777 -0.125714 -0.760722]
# [ 1.638509 -0.601126 -1.043931 -1.33095 ]]
DataFrame의 desribe()를 통해 각 컬럼의 통계적인 수치를 요약하여 보여줄 수 있습니다.
- count: 데이터 개수
- mean: 평균값
- std: 표준편차
- min: 최소값
- 25%: 1사분위값
- 50%: 중앙값
- 75%: 3사분위값
- max: 최대값
df.descrbie()
# A B C D
# count 6.000000 6.000000 6.000000 6.000000
# mean 0.245593 0.087534 -0.072482 -0.297124
# std 1.407466 1.423367 0.549378 0.651149
# min -1.682384 -0.958267 -1.043931 -1.330950
# 25% -0.805462 -0.818679 -0.146146 -0.623695
# 50% 0.491811 -0.313566 -0.070392 -0.165601
# 75% 1.451725 0.113514 0.301730 0.110631
# max 1.638509 2.841777 0.495447 0.453095
DataFrame의 .T 속성은 values를 Transpose한 결과를 보여줍니다. Transpose는 인덱스를 컬럼으로, 컬럼을 인덱스로 변경하여 보여주는 것입니다.
df.T
# 2013-01-01 2013-01-02 2013-01-03 2013-01-04 2013-01-05 2013-01-06
# A 1.571507 -1.037697 -1.682384 -0.108757 1.092380 1.638509
# B 0.160021 -0.891196 -0.026006 -0.958267 2.841777 -0.601126
# C -0.015071 0.495447 -0.152957 0.407331 -0.125714 -1.043931
# D -0.118588 0.453095 -0.212614 0.187037 -0.760722 -1.330950
DataFrame의 sort_index()를 통해 인덱스 또는 컬럼의 이름으로 정렬을 할 수도 있습니다.
axis: 축 기준 정보 (0: 인덱스 기준, 1: 컬럼 기준)ascending: 정렬 방식 (false : 내림차순, true: 오름차순)
df.sort_index(axis=1, ascending=False)
# D C B A
# 2013-01-01 -0.118588 -0.015071 0.160021 1.571507
# 2013-01-02 0.453095 0.495447 -0.891196 -1.037697
# 2013-01-03 -0.212614 -0.152957 -0.026006 -1.682384
# 2013-01-04 0.187037 0.407331 -0.958267 -0.108757
# 2013-01-05 -0.760722 -0.125714 2.841777 1.092380
# 2013-01-06 -1.330950 -1.043931 -0.601126 1.638509
DataFrame의 sort_values() 를 이용하여 value 값 기준으로 정렬할 수도 있습니다.
by: 데이터 정렬에 기준이 되는 컬럼
# 'B' 컬럼 기준으로 정렬됩니다.
df.sort_values(by='B')
# A B C D
# 2013-01-04 -0.108757 -0.958267 0.407331 0.187037
# 2013-01-02 -1.037697 -0.891196 0.495447 0.453095
# 2013-01-06 1.638509 -0.601126 -1.043931 -1.330950
# 2013-01-03 -1.682384 -0.026006 -0.152957 -0.212614
# 2013-01-01 1.571507 0.160021 -0.015071 -0.118588
# 2013-01-05 1.092380 2.841777 -0.125714 -0.760722
3. 데이터 선택하기 (Selection)
이 장에 대해 자세한 설명은 Indexing and Selecting Data와 MultiIndex / Advanced Indexing을 확인하세요.
데이터 가져오기 - Getting
컬럼을 기준으로 데이터를 가져올 수 있습니다.
# df.A 또는 df['A'] 로 컬럼의 데이터를 얻을 수 있습니다.
df['A']
# 2013-01-01 1.571507
# 2013-01-02 -1.037697
# 2013-01-03 -1.682384
# 2013-01-04 -0.108757
# 2013-01-05 1.092380
# 2013-01-06 1.638509
# Freq: D, Name: A, dtype: float64

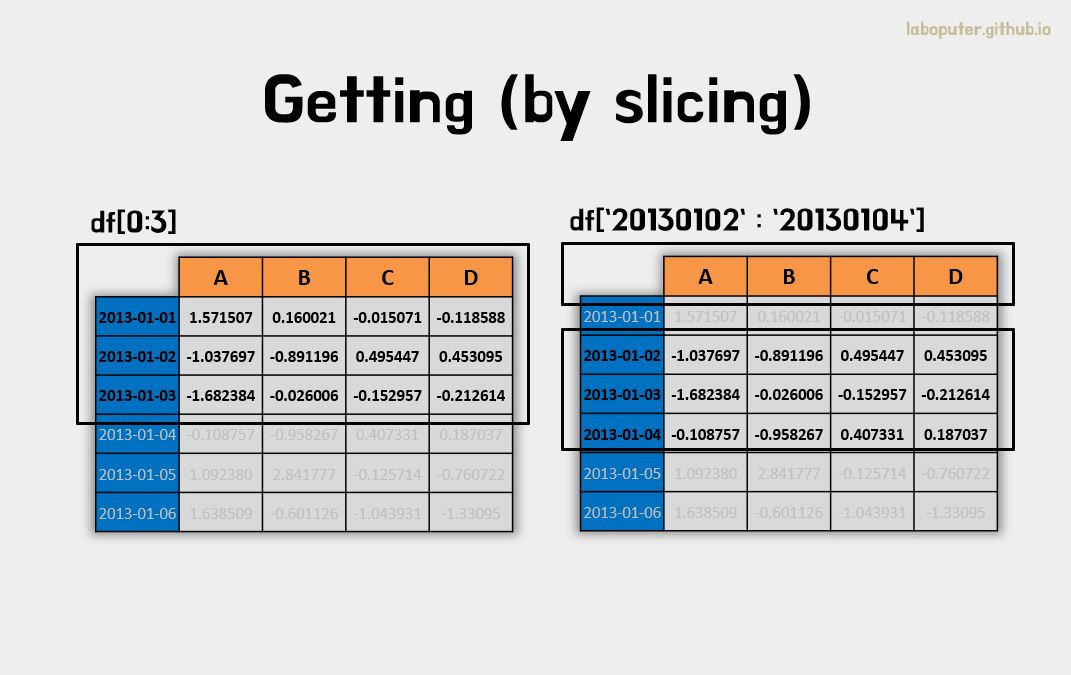
[]을 이용하여 특정 범위의 행을 슬라이싱할 수 있습니다.
# 0번~2번 행을 슬라이싱 합니다.
df[0:3]
# A B C D
# 2013-01-01 1.571507 0.160021 -0.015071 -0.118588
# 2013-01-02 -1.037697 -0.891196 0.495447 0.453095
# 2013-01-03 -1.682384 -0.026006 -0.152957 -0.212614
# 20130102 부터 20130104 까지 행을 슬라이싱 합니다.
df['20130102':'20130104']
# A B C D
# 2013-01-02 -1.037697 -0.891196 0.495447 0.453095
# 2013-01-03 -1.682384 -0.026006 -0.152957 -0.212614
# 2013-01-04 -0.108757 -0.958267 0.407331 0.187037
이름으로 데이터 가져오기 - Selection by label
이 장에 대해 자세한 설명은 Selection by Label을 참고하세요.
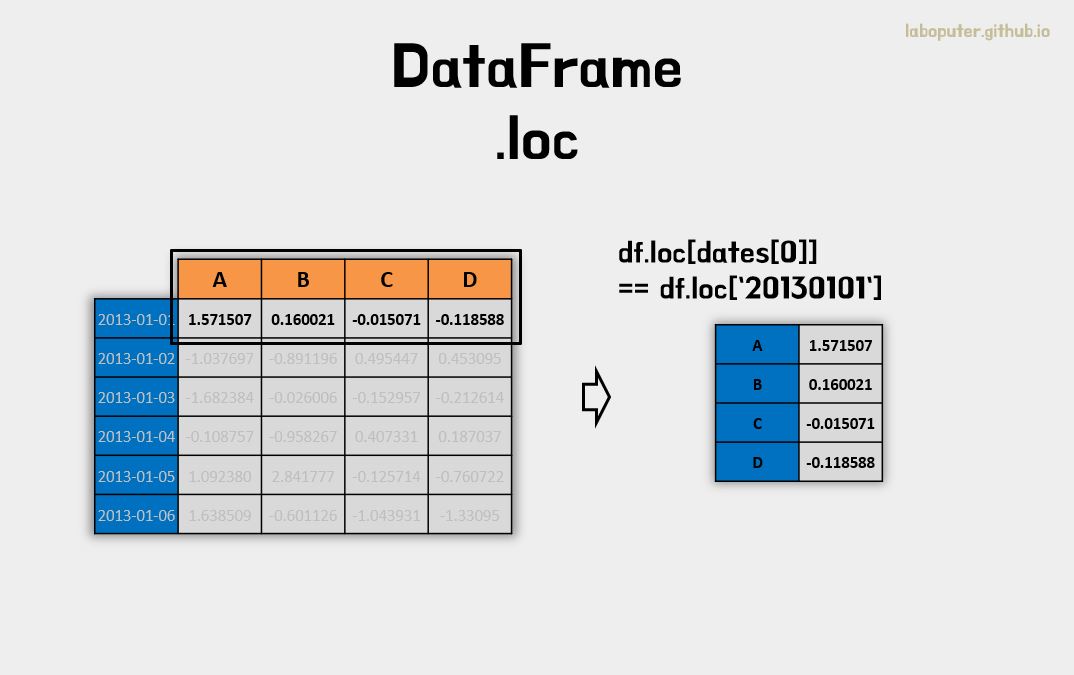
이름(Label)로 가져오는 것은 DataFrame의 .loc 속성을 이용합니다.
.loc은 2차원으로 구성되어 있습니다. .loc[인덱스명, 컬럼명] 형식으로 접근가능 합니다. 만약 인덱스명만 입력하면 행의 값으로 결과가 나옵니다. 또한 인덱스명, 컬럼명을 선택할때 리스트 형식으로 멀티인덱싱이 가능합니다.
# 0번 인덱스명으로 데이터 가져오기
df.loc[dates[0]]
# A 1.571507
# B 0.160021
# C -0.015071
# D -0.118588
# Name: 2013-01-01 00:00:00, dtype: float64
# 행은 전체 선택, 컬럼명은 'A', 'B' 두개 선택하여 가져오기
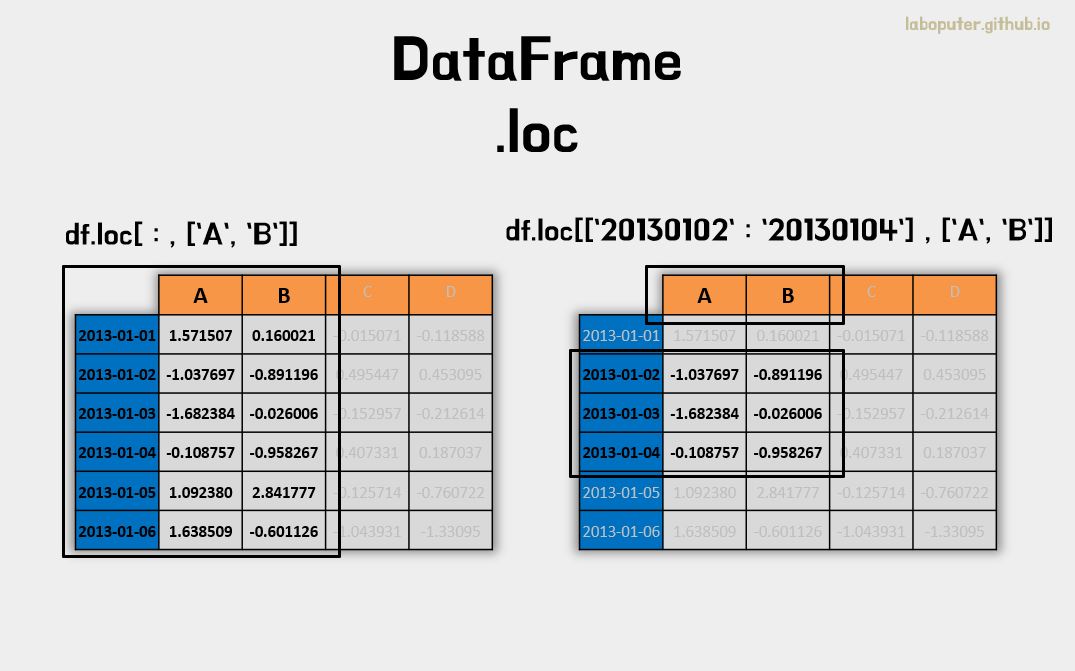
df.loc[:,['A','B']]
# A B
# 2013-01-01 1.571507 0.160021
# 2013-01-02 -1.037697 -0.891196
# 2013-01-03 -1.682384 -0.026006
# 2013-01-04 -0.108757 -0.958267
# 2013-01-05 1.092380 2.841777
# 2013-01-06 1.638509 -0.601126
# 행은 슬라이싱으로 범위 선택, 컬럼명은 'A','B' 선택
df.loc['20130102':'20130104',['A','B']]
# A B
# 2013-01-02 -1.037697 -0.891196
# 2013-01-03 -1.682384 -0.026006
# 2013-01-04 -0.108757 -0.958267
# 행은 20130102 선택, 컬럼명은 'A', 'B' 선택
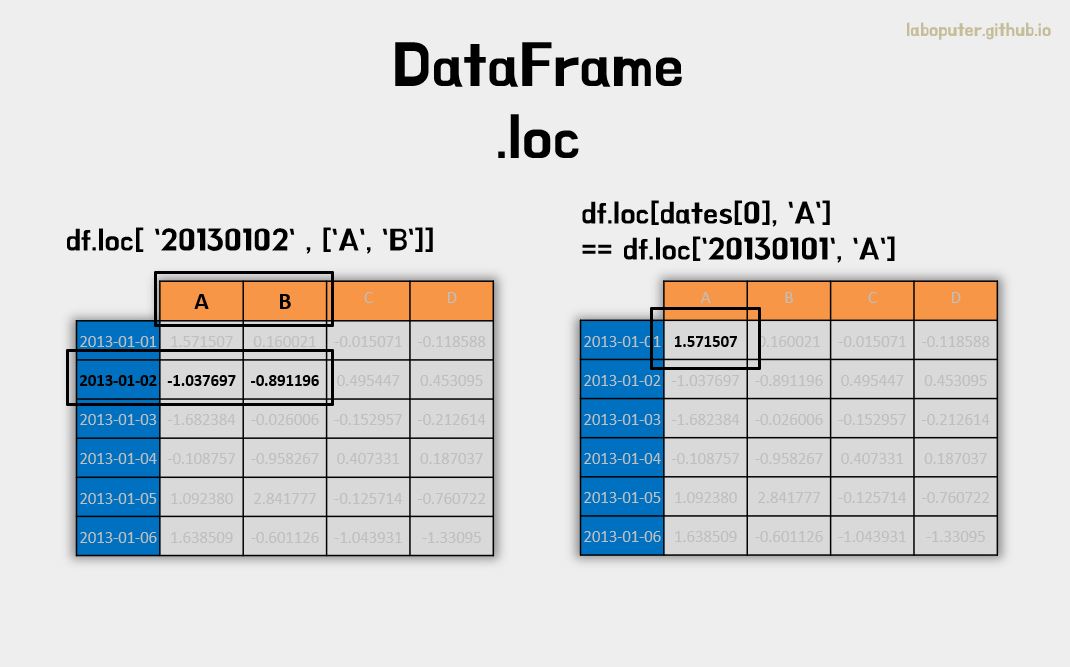
df.loc['20130102',['A','B']]
# A -1.037697
# B -0.891196
# Name: 2013-01-02 00:00:00, dtype: float64
인덱스명, 컬럼명을 하나씩 선택하면 스칼라값을 가져올 수 있습니다.
# 행은 첫번째 선택, 컬럼은 'A' 선택
df.loc[dates[0],'A']
# 1.571506676720408
인덱스로 데이터 가져오기 - Selection by Position
여기서 말하는 인덱스는 위치(숫자) 정보를 말합니다.
이 장에 대해 자세한 설명은 Selection by Position을 확인하세요.
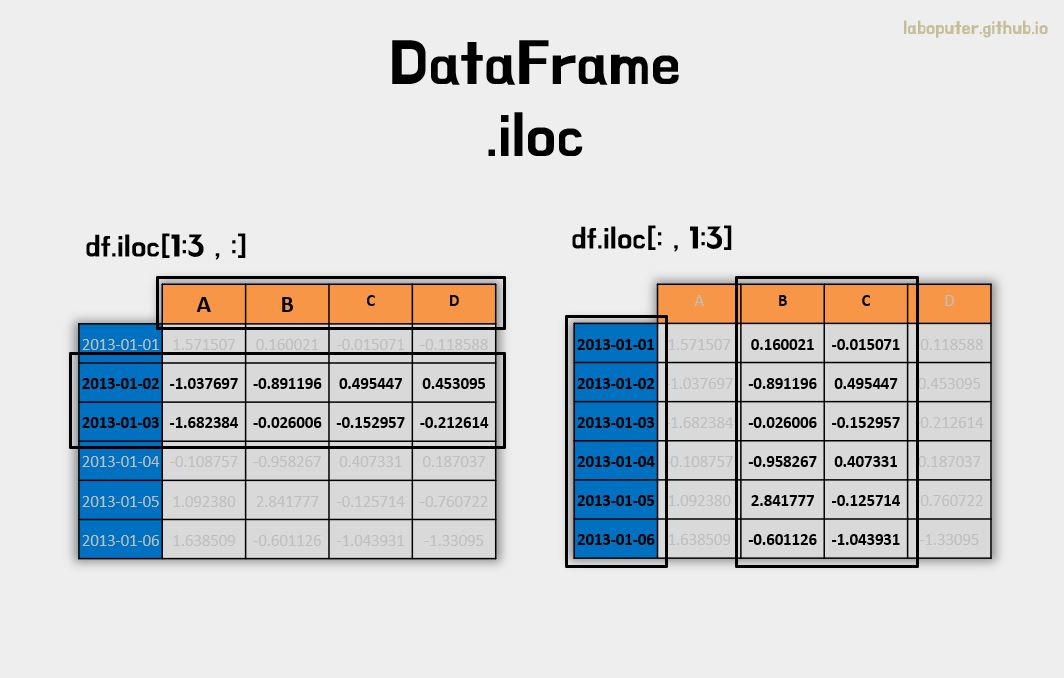
DataFrame의 .iloc 속성을 이용합니다.
.iloc도 2차원 형태로 구성되어 있어 1번째 인덱스는 행의 번호를, 2번째 인덱스는 컬럼의 번호를 의미합니다. 마찬가지로 멀티인덱싱도 가능합니다.
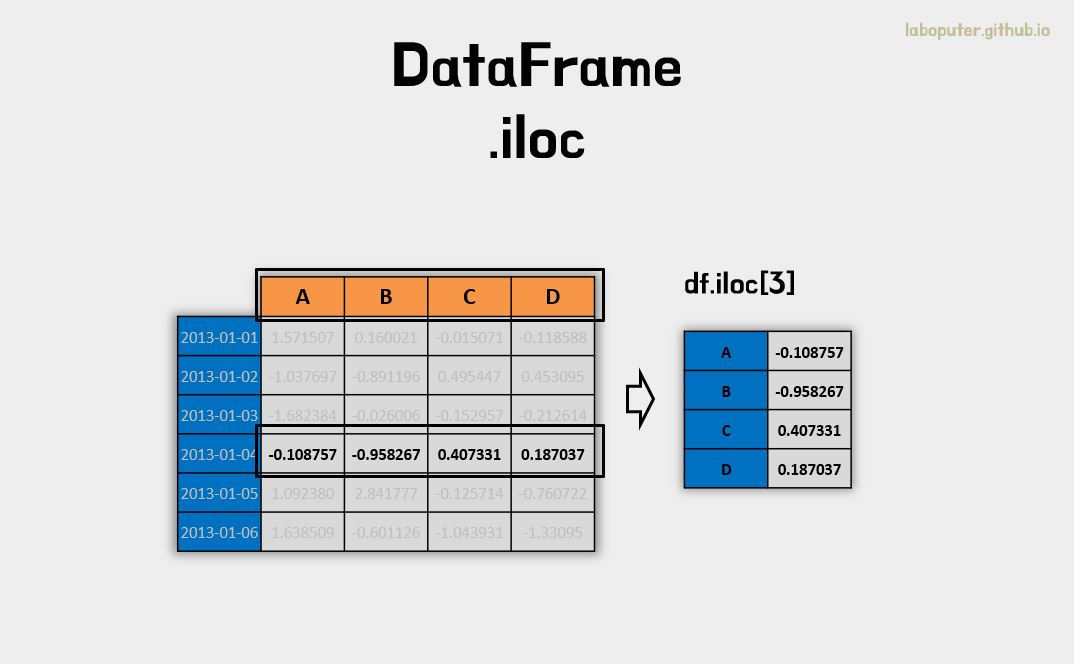
# 3번 인덱스 행 가져오기
df.iloc[3]
# A -0.108757
# B -0.958267
# C 0.407331
# D 0.187037
# Name: 2013-01-04 00:00:00, dtype: float64
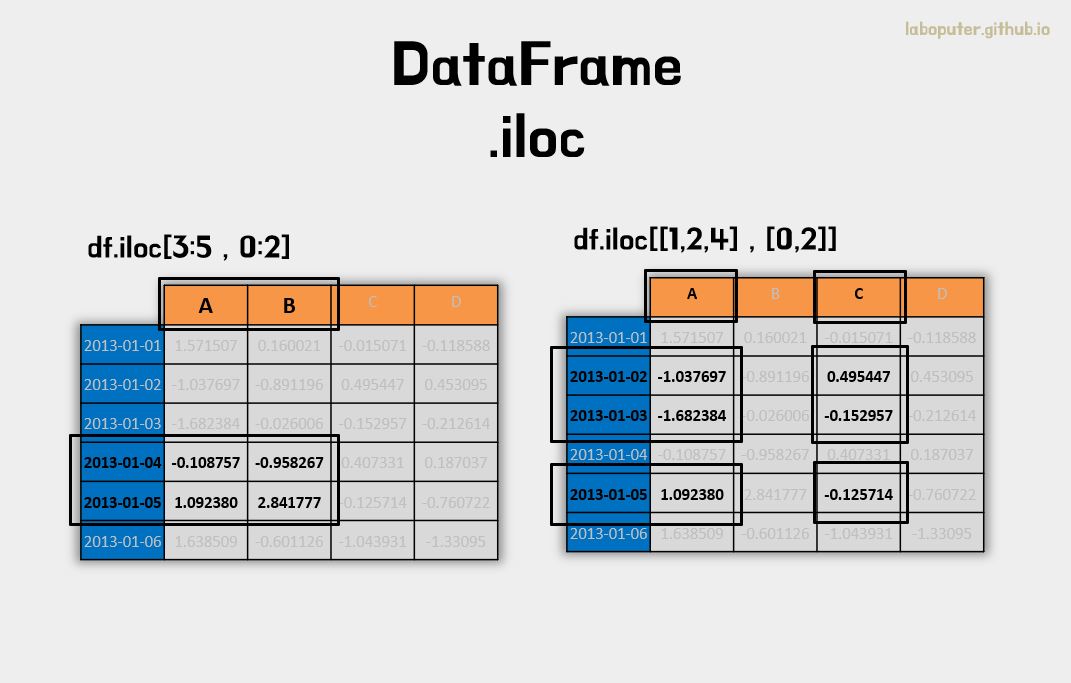
# 3~4번 인덱스 행, 0~1번 컬럼 값 가져오기
df.iloc[3:5,0:2]
# A B
# 2013-01-04 -0.108757 -0.958267
# 2013-01-05 1.092380 2.841777
# 1,2,4번 인덱스 행과 0,2번 인덱스 컬럼 가져오기
df.iloc[[1,2,4],[0,2]]
# A C
# 2013-01-02 -1.037697 0.495447
# 2013-01-03 -1.682384 -0.152957
# 2013-01-05 1.092380 -0.125714
# 1~2번 인덱스 행과 전체 컬럼 값 가져오기
df.iloc[1:3,:]
# A B C D
# 2013-01-02 -1.037697 -0.891196 0.495447 0.453095
# 2013-01-03 -1.682384 -0.026006 -0.152957 -0.212614
# 전체 행과 1~2번 인덱스 컬럼 값 가져오기
df.iloc[:,1:3]
# B C
# 2013-01-01 0.160021 -0.015071
# 2013-01-02 -0.891196 0.495447
# 2013-01-03 -0.026006 -0.152957
# 2013-01-04 -0.958267 0.407331
# 2013-01-05 2.841777 -0.125714
# 2013-01-06 -0.601126 -1.043931
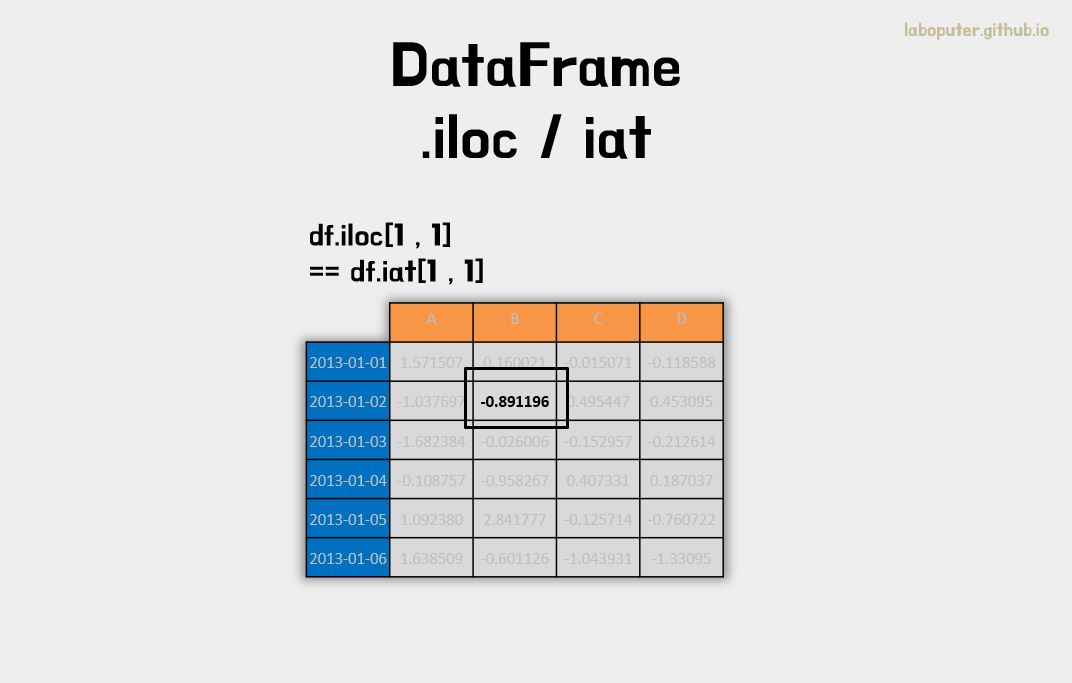
# 1번 행, 1번 컬럼 값 가져오기
df.iloc[1,1]
# -0.89119558600132898
# 위와 동일하지만 스칼라값을 가져오는 속도가 .iat이 빠르다고 합니다.
df.iat[1,1]
# 0.89119558600132898
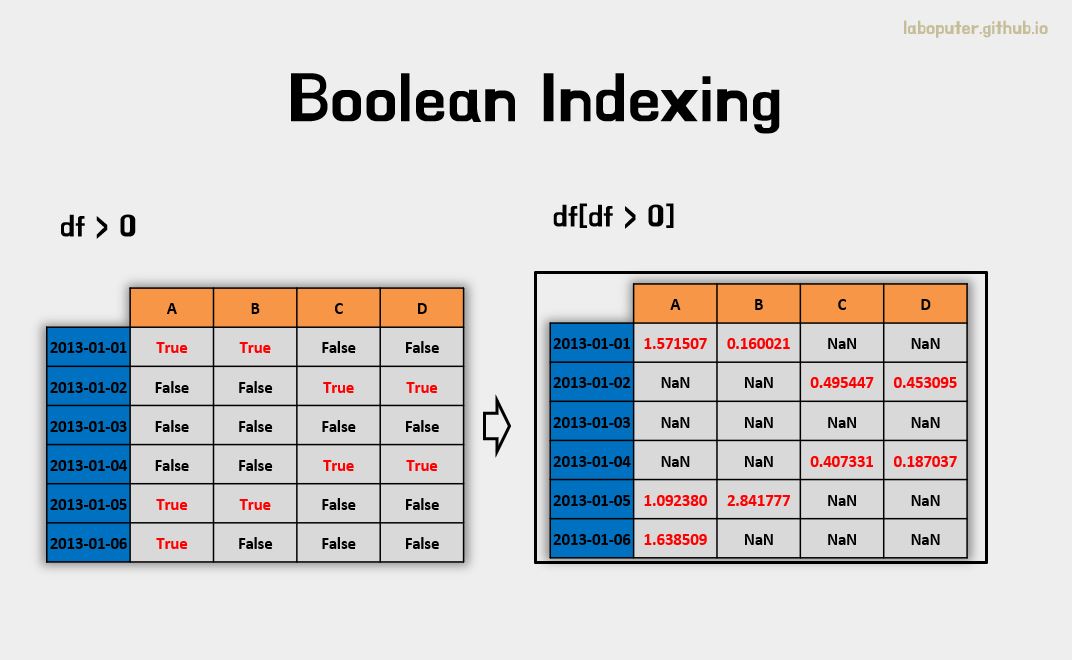
조건으로 가져오기 - Boolean Indexing
하나의 컬럼의 값에 따라 행들을 선택할 수 있습니다.
df[df['A'] > 0]
# A B C D
# 2013-01-01 1.571507 0.160021 -0.015071 -0.118588
# 2013-01-05 1.092380 2.841777 -0.125714 -0.760722
# 2013-01-06 1.638509 -0.601126 -1.043931 -1.330950

DataFrame의 값 조건에 해당하는 것만 선택할 수도 있습니다.
df[df > 0]
# A B C D
# 2013-01-01 1.571507 0.160021 NaN NaN
# 2013-01-02 NaN NaN 0.495447 0.453095
# 2013-01-03 NaN NaN NaN NaN
# 2013-01-04 NaN NaN 0.407331 0.187037
# 2013-01-05 1.092380 2.841777 NaN NaN
# 2013-01-06 1.638509 NaN NaN NaN
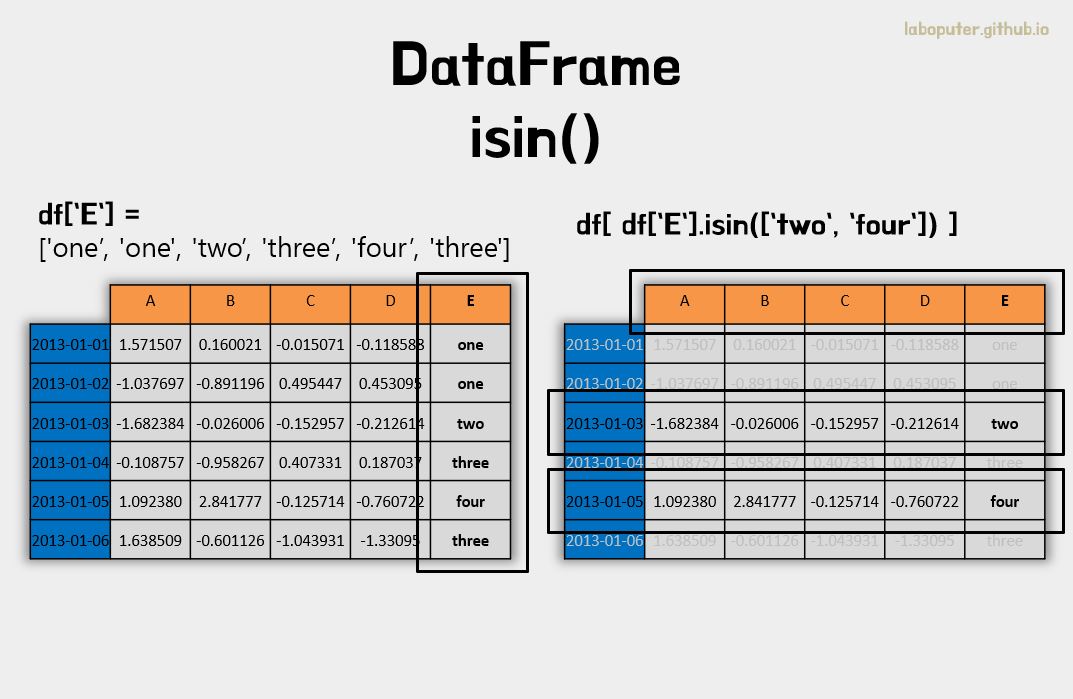
isin()을 이용하여 필터링을 할 수 있습니다.
# df를 복사합니다.
df2 = df.copy()
# 새로운 컬럼 E에 값을 넣습니다.
df2['E'] = ['one','one', 'two','three','four','three']
# A B C D E
# 2013-01-01 1.571507 0.160021 -0.015071 -0.118588 one
# 2013-01-02 -1.037697 -0.891196 0.495447 0.453095 one
# 2013-01-03 -1.682384 -0.026006 -0.152957 -0.212614 two
# 2013-01-04 -0.108757 -0.958267 0.407331 0.187037 three
# 2013-01-05 1.092380 2.841777 -0.125714 -0.760722 four
# 2013-01-06 1.638509 -0.601126 -1.043931 -1.330950 three
# 컬럼 E에 들어있는것만 필터링합니다.
df2[df2['E'].isin(['two','four'])]
# A B C D E
# 2013-01-03 -1.682384 -0.026006 -0.152957 -0.212614 two
# 2013-01-05 1.092380 2.841777 -0.125714 -0.760722 four
데이터 변경하기 - Setting
DataFrame 안에 있는 데이터를 변경하려고 합니다.
우선 Series를 하나 만들고 기존에 생성했던 DataFrame에 붙여보겠습니다.
s1 = pd.Series([1,2,3,4,5,6], index=pd.date_range('20130102',periods=6))
# 2013-01-02 1
# 2013-01-03 2
# 2013-01-04 3
# 2013-01-05 4
# 2013-01-06 5
# 2013-01-07 6
# Freq: D, dtype: int64
# Series를 'F' 컬럼에 넣는다.
df['F'] = s1
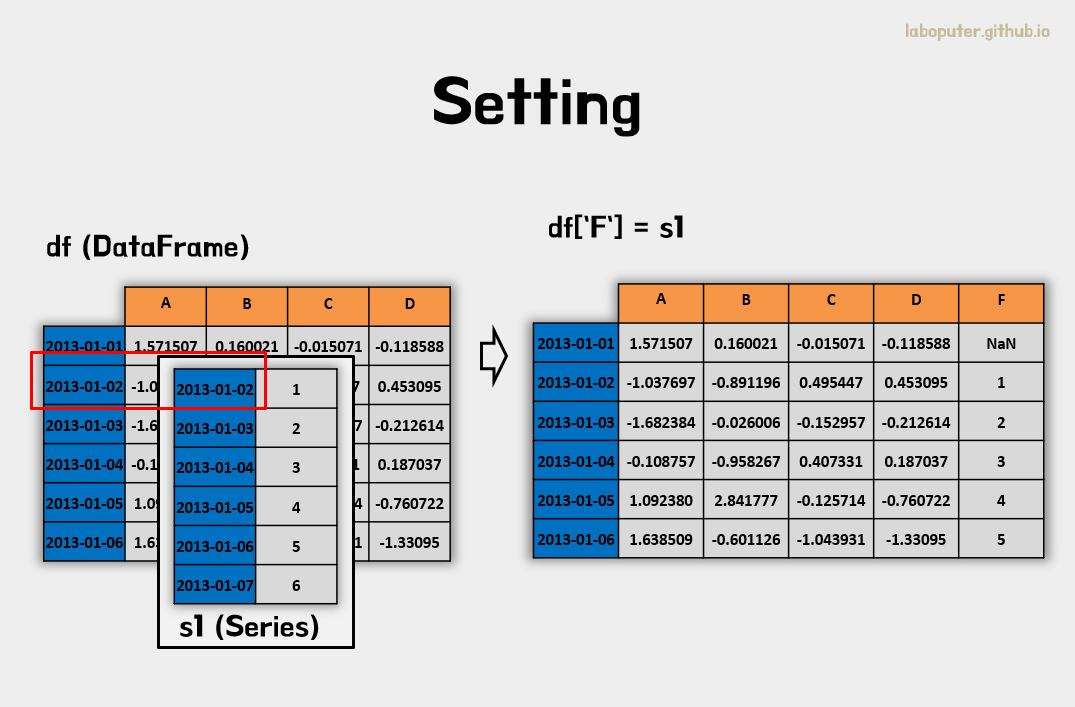
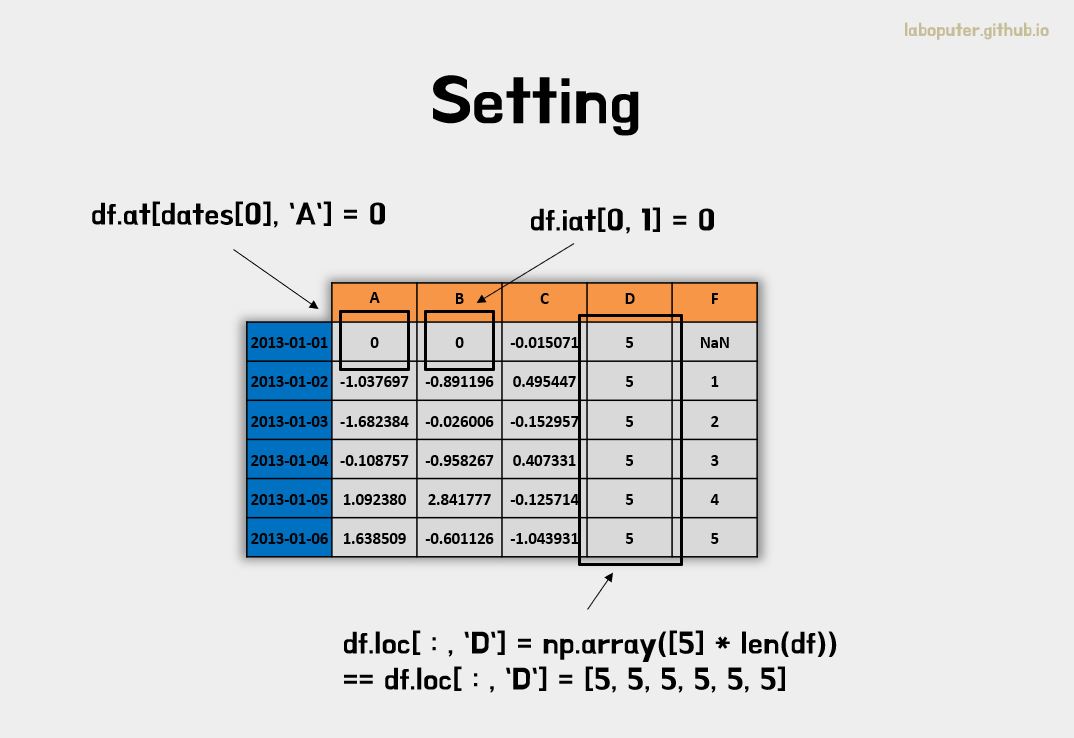
데이터 선택하기와 같은 속성 at, iat, loc, iloc 등을 그대로 사용하면 됩니다.
# 0번째 인덱스, 'A' 컬럼을 0으로 변경
df.at[dates[0],'A'] = 0
# 0번째 인덱스, 1번째 컬럼을 0으로 변경
df.iat[0,1] = 0
# 전체 인덱스, 'D' 컬럼 데이터를 변경
df.loc[:,'D'] = np.array([5] * len(df))
df
# A B C D F
# 2013-01-01 0.000000 0.000000 -0.015071 5 NaN
# 2013-01-02 -1.037697 -0.891196 0.495447 5 1.0
# 2013-01-03 -1.682384 -0.026006 -0.152957 5 2.0
# 2013-01-04 -0.108757 -0.958267 0.407331 5 3.0
# 2013-01-05 1.092380 2.841777 -0.125714 5 4.0
# 2013-01-06 1.638509 -0.601126 -1.043931 5 5.0
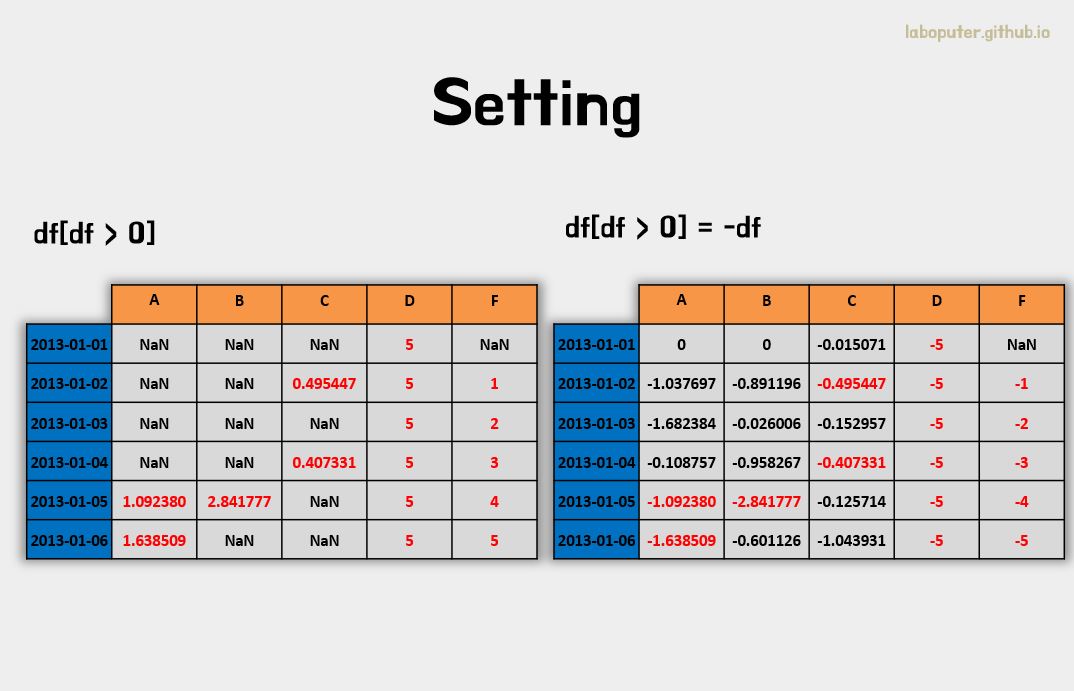
조건문(where)으로 선택하여 데이터를 변경할 수도 있습니다.
# 기존 DataFrame 복사
df2 = df.copy()
# 0보다 큰 데이터만 음수로 변경
df2[df2 > 0] = -df2
df2
# A B C D F
# 2013-01-01 0.000000 0.000000 -0.015071 -5 NaN
# 2013-01-02 -1.037697 -0.891196 -0.495447 -5 -1.0
# 2013-01-03 -1.682384 -0.026006 -0.152957 -5 -2.0
# 2013-01-04 -0.108757 -0.958267 -0.407331 -5 -3.0
# 2013-01-05 -1.092380 -2.841777 -0.125714 -5 -4.0
# 2013-01-06 -1.638509 -0.601126 -1.043931 -5 -5.0
4. 결측 데이터 (Missing Data)
데이터를 다루다보면 값이 없는 경우가 자주 생깁니다. 데이터가 없는 것을 결측 데이터라고 합니다. 판다스에서는 이러한 값이 NaN 으로 표현됩니다. 기본적으로 결측 데이터가 있는 경우에는 연산에 포함되지 않습니다.
이 장에 대해 자세한 설명은 Missing Data section을 확인하세요.
reindex()을 통해 컬럼이나 인덱스를 추가하거나, 삭제하거나 변경하는 등의 작업을 진행할 수 있습니다. 먼저 결측 데이터를 만들기 위해 ‘E’ 컬럼을 생성합니다.
df1 = df.reindex(index=dates[0:4], columns=list(df.columns) + ['E'])
df1.loc[dates[0]:dates[1],'E'] = 1
df1
# A B C D F E
# 2013-01-01 0.000000 0.000000 -0.015071 5 NaN 1.0
# 2013-01-02 -1.037697 -0.891196 0.495447 5 1.0 1.0
# 2013-01-03 -1.682384 -0.026006 -0.152957 5 2.0 NaN
# 2013-01-04 -0.108757 -0.958267 0.407331 5 3.0 NaN
DataFrame의 dropna()를 통해 결측데이터를 삭제(drop)할 수 있습니다. how='any'는 값들 중 하나라도 NaN인 경우 삭제입니다. how='all'은 전체가 NaN인 경우 삭제입니다.
df1.dropna(how='any')
# A B C D F E
# 2013-01-02 -1.037697 -0.891196 0.495447 5 1.0 1.0
DataFrame의 fillna()를 통해 결측데이터에 값을 넣을 수도 있습니다.
df1.fillna(value=5)
# A B C D F E
# 2013-01-01 0.000000 0.000000 -0.015071 5 5.0 1.0
# 2013-01-02 -1.037697 -0.891196 0.495447 5 1.0 1.0
# 2013-01-03 -1.682384 -0.026006 -0.152957 5 2.0 5.0
# 2013-01-04 -0.108757 -0.958267 0.407331 5 3.0 5.0
pd.isnull()을 통해 결측데이터 여부를 Boolean으로 가져올 수 있습니다.
pd.isnull(df1)
# A B C D F E
# 2013-01-01 False False False False True False
# 2013-01-02 False False False False False False
# 2013-01-03 False False False False False True
# 2013-01-04 False False False False False True
5. 데이터 연산 (Operations)
이 장에 대해 자세한 설명은 Basic section on Binary Ops을 참고하세요.
통계지표 - Stats
일반적으로 결측데이터는 빼고 계산됩니다.
DataFrame의 mean()으로 평균을 구할 수 있습니다.
df.mean()
# A -0.016325
# B 0.060864
# C -0.072482
# D 5.000000
# F 3.000000
# dtype: float64
같은 mean()을 다른 축(axis)에 대한 평균을 구할 수 있습니다. 여기서 축이란 0은 컬럼 기준, 1은 인덱스 기준을 말합니다.
# axis = 1로 평균 구하기
df.mean(1)
# 2013-01-01 1.246232
# 2013-01-02 0.913311
# 2013-01-03 1.027731
# 2013-01-04 1.468061
# 2013-01-05 2.561689
# 2013-01-06 1.998690
# Freq: D, dtype: float64
만약 다른 차원의 오브젝트들 간 연산이 필요한 경우 축만 맞춰진다면 자동으로 연산을 수행합니다.
# 데이터 시프트 연산 (2개씩 밀립니다.)
s = pd.Series([1,3,5,np.nan,6,8], index=dates).shift(2)
# 2013-01-01 NaN
# 2013-01-02 NaN
# 2013-01-03 1.0
# 2013-01-04 3.0
# 2013-01-05 5.0
# 2013-01-06 NaN
# Freq: D, dtype: float64
# DataFrame와 Series를 index 축 기준으로 빼기 연산
df.sub(s, axis='index')
# A B C D F
# 2013-01-01 NaN NaN NaN NaN NaN
# 2013-01-02 NaN NaN NaN NaN NaN
# 2013-01-03 -2.682384 -1.026006 -1.152957 4.0 1.0
# 2013-01-04 -3.108757 -3.958267 -2.592669 2.0 0.0
# 2013-01-05 -3.907620 -2.158223 -5.125714 0.0 -1.0
# 2013-01-06 NaN NaN NaN NaN NaN
함수 적용 - Apply
데이터에 대해 정의된 함수들이나 lamdba 식을 이용하여 새로운 함수도 적용할 수 있습니다.
# 각 컬럼별(기본 axis = 0은 컬럼 기준) 누적합을 구합니다.
df.apply(np.cumsum)
# A B C D F
# 2013-01-01 0.000000 0.000000 -0.015071 5 NaN
# 2013-01-02 -1.037697 -0.891196 0.480376 10 1.0
# 2013-01-03 -2.720081 -0.917202 0.327419 15 3.0
# 2013-01-04 -2.828838 -1.875469 0.734750 20 6.0
# 2013-01-05 -1.736458 0.966308 0.609036 25 10.0
# 2013-01-06 -0.097949 0.365182 -0.434895 30 15.0
# lambda 식을 이용하여 max-min의 값을 구합니다.
df.apply(lambda x: x.max() - x.min())
# A 3.320893
# B 3.800044
# C 1.539378
# D 0.000000
# F 4.000000
# dtype: float64
히스토그램 - Histogramming
이 장에 대해 자세한 설명은 Histogramming and Discretization을 참고하세요.
Series 데이터의 각 값이 어떤 분포를 이루는지 히스토그램 형식으로 볼 수 있습니다.
s = pd.Series(np.random.randint(0, 7, size=10))
# 0 2
# 1 0
# 2 5
# 3 3
# 4 5
# 5 5
# 6 2
# 7 2
# 8 3
# 9 5
# dtype: int64
s.value_counts()
# 5 4
# 2 3
# 3 2
# 0 1
# dtype: int64
문자열 처리 - String Methods
이 장에 대해 자세한 설명은 regular expressions와 Vectorized String Methods 을 참고하세요.
Series에서 문자열 관련된 함수들은 .str 속성에 포함되어 있습니다.
str.lower()를 통해 문자를 소문자로 변경할 수 있습니다.
s = pd.Series(['A', 'B', 'C', 'Aaba', 'Baca', np.nan, 'CABA', 'dog', 'cat'])
s.str.lower()
# 0 a
# 1 b
# 2 c
# 3 aaba
# 4 baca
# 5 NaN
# 6 caba
# 7 dog
# 8 cat
# dtype: object
6. 데이터 합치기 (Merge)
판다스는 Series와 DataFrame 간에 쉽게 데이터를 합칠 수 있도록 join과 merge와 같은 연산을 제공합니다.
이어붙이기 - Concat
이 장에 대해 자세한 설명은 Merging section을 확인하세요.
concat()을 이용하여 이어붙이는 연산(Concatenating)을 할 수 있습니다.
df = pd.DataFrame(np.random.randn(10, 4))
# 0 1 2 3
# 0 -0.234987 -0.373520 -2.331217 -0.011025
# 1 -0.594832 -0.056876 0.511321 -0.637962
# 2 0.829543 -0.136714 0.817715 -0.418866
# 3 1.363304 -1.189597 0.616684 -1.277144
# 4 0.328333 -0.249324 -0.003902 0.665675
# 5 -0.420494 0.055223 1.485964 -1.320391
# 6 -1.583362 0.117909 0.332279 0.362941
# 7 0.479388 -0.369535 -0.939108 1.142691
# 8 0.765936 0.750054 0.634936 -1.405519
# 9 -1.262849 0.883082 -0.200222 -0.132803
# 위에서 생성한 DataFrame을 여러개로 분리합니다.
pieces = [df[:3], df[3:7], df[7:]]
# concat()을 이용하여 다시 이어붙일 수 있습니다.
pd.concat(pieces)
# 0 1 2 3
# 0 -0.234987 -0.373520 -2.331217 -0.011025
# 1 -0.594832 -0.056876 0.511321 -0.637962
# 2 0.829543 -0.136714 0.817715 -0.418866
# 3 1.363304 -1.189597 0.616684 -1.277144
# 4 0.328333 -0.249324 -0.003902 0.665675
# 5 -0.420494 0.055223 1.485964 -1.320391
# 6 -1.583362 0.117909 0.332279 0.362941
# 7 0.479388 -0.369535 -0.939108 1.142691
# 8 0.765936 0.750054 0.634936 -1.405519
# 9 -1.262849 0.883082 -0.200222 -0.132803
조인 - Join
SQL에서 자주 사용하는 join 연산도 제공됩니다.
이 장에 대해 자세한 설명은 Database style joining을 참고하세요.
left = pd.DataFrame({'key': ['foo', 'foo'], 'lval': [1, 2]})
# key lval
# 0 foo 1
# 1 foo 2
right = pd.DataFrame({'key': ['foo', 'foo'], 'rval': [4, 5]})
# key rval
# 0 foo 4
# 1 foo 5
# 위에서 생성한 left, right를 'key' 컬럼값 기준으로 조인합니다.
pd.merge(left, right, on='key')
# key lval rval
# 0 foo 1 4
# 1 foo 1 5
# 2 foo 2 4
# 3 foo 2 5
key가 다른 경우도 보겠습니다.
left = pd.DataFrame({'key': ['foo', 'bar'], 'lval': [1, 2]})
# key lval
# 0 foo 1
# 1 bar 2
right = pd.DataFrame({'key': ['foo', 'bar'], 'rval': [4, 5]})
# key rval
# 0 foo 4
# 1 bar 5
pd.merge(left, right, on='key')
# key lval rval
# 0 foo 1 4
# 1 bar 2 5
아래 예제처럼 조인 연산 자체가 key가 같은 두 테이블을 합쳐서 하나의 테이블로 확인하기 위해 사용하는데, 만약 Key가 중복된 경우가 있으면 어떻게 나오는지는 위 예제로 확인하실 수 있습니다.
7. 그룹화 (Grouping)
group by에 관련된 내용은 아래와 같은 과정을 말합니다.
- Spltting : 특정 기준으로 데이터 나누기
- applying : 각 그룹에 함수를 독립적으로 적용시키는 것
- Combining : 결과를 데이터 구조로 저장하는 것
이 장에 대해 자세한 설명은 Grouping section을 참고하세요.
먼저 DataFrame을 하나 생성하겠습니다.
df = pd.DataFrame({'A' : ['foo', 'bar', 'foo', 'bar', 'foo', 'bar', 'foo', 'foo'],
'B' : ['one', 'one', 'two', 'three','two', 'two', 'one', 'three'],
'C' : np.random.randn(8),
'D' : np.random.randn(8)})
# A B C D
# 0 foo one -0.740768 2.281787
# 1 bar one -0.501289 1.099814
# 2 foo two -0.156649 -0.476144
# 3 bar three 0.077314 0.448811
# 4 foo two 0.072001 -1.212766
# 5 bar two -1.794411 -0.726346
# 6 foo one 1.950104 -0.884756
# 7 foo three 0.537576 0.536286
특정 컬럼 기준으로 먼저 그룹화를 진행한 후 sum()을 적용합니다.
#A 컬럼이 같은 것끼리 묶고, sum()
df.groupby('A').sum()
# C D
# A
# bar -2.218387 0.822278
# foo 1.662263 0.244406
# 'A기준으로 묶고'. 'B' 기준으로 다시 묶은 후 sum()
df.groupby(['A','B']).sum()
# C D
# A B
# bar one -0.501289 1.099814
# three 0.077314 0.448811
# two -1.794411 -0.726346
# foo one 1.209336 1.397031
# three 0.537576 0.536286
# two -0.084648 -1.688910
8. 데이터 구조 변경하기 (Reshaping)
이 장에 대해 자세한 설명은 Hierarchical Indexing와 Reshaping을 확인하세요.
스택 - Stack
먼저 새로운 DataFrame을 하나 생성하겠습니다.
tuples = list(zip(*[['bar', 'bar', 'baz', 'baz', 'foo', 'foo', 'qux', 'qux'],
['one', 'two', 'one', 'two', 'one', 'two', 'one', 'two']]))
# 각 리스트에서 첫번째를 'first'로 두번째를 'second'로 멀티인덱스를 만듭니다.
index = pd.MultiIndex.from_tuples(tuples, names=['first', 'second'])
# 두 개의 컬럼을 생성하고 랜덤값을 부여합니다.
df = pd.DataFrame(np.random.randn(8, 2), index=index, columns=['A', 'B'])
df2 = df[:4]
# A B
# first second
# bar one 0.438217 -0.418822
# two 1.034927 -0.464648
# baz one 0.463575 -0.141918
# two 0.490648 0.247615
DataFrame의 stack()은 모든 데이터들을 인덱스 레벨로 변형합니다. 이를 압축(compresses)한다고 표현합니다.
stacked = df2.stack()
# first second
# bar one A 0.438217
# B -0.418822
# two A 1.034927
# B -0.464648
# baz one A 0.463575
# B -0.141918
# two A 0.490648
# B 0.247615
# dtype: float64
unstack() 을 통해 “stacked”된 DataFrame 이나 Series 를 원래 형태로 되돌릴 수 있습니다. 되돌리는(압축 해제) 것의 레벨을 정할 수 있습니다.
# 원래 상태로 되돌립니다. (레벨 -1)
stacked.unstack()
# A B
# first second
# bar one 0.438217 -0.418822
# two 1.034927 -0.464648
# baz one 0.463575 -0.141918
# two 0.490648 0.247615
# 레벨1은 second 인덱스가 해제되어 one과 two 컬럼이 생깁니다.
stacked.unstack(1)
# second one two
# first
# bar A 0.438217 1.034927
# B -0.418822 -0.464648
# baz A 0.463575 0.490648
# B -0.141918 0.247615
# 레벨0은 first 인덱스가 해제되어 bar와 baz 컬럼이 생깁니다.
stacked.unstack(0)
# first bar baz
# second
# one A 0.438217 0.463575
# B -0.418822 -0.141918
# two A 1.034927 0.490648
# B -0.464648 0.247615
피벗 테이블 - Pivot Tables
이 장에 대해 자세한 설명은 Pivot Tables을 참고하세요.
우선 DataFrame을 하나 생성하겠습니다.
df = pd.DataFrame({'A' : ['one', 'one', 'two', 'three'] * 3,
'B' : ['A', 'B', 'C'] * 4,
'C' : ['foo', 'foo', 'foo', 'bar', 'bar', 'bar'] * 2,
'D' : np.random.randn(12),
'E' : np.random.randn(12)})
# A B C D E
# 0 one A foo -0.268332 -1.378239
# 1 one B foo -1.168934 0.263587
# 2 two C foo 1.245084 0.882631
# 3 three A bar 1.339747 0.770703
# 4 one B bar 0.005996 0.501930
# 5 one C bar 0.083572 -0.151838
# 6 two A foo 1.172619 1.110582
# 7 three B foo -0.210904 -0.200479
# 8 one C foo 0.166766 0.308271
# 9 one A bar 0.516837 0.869884
# 10 two B bar -0.667602 0.584587
# 11 three C bar -0.848954 0.609278
pd.pivot_table()을 통해 새로운 피벗으로 테이블을 만들 수 있습니다.
pd.pivot_table(df, values='D', index=['A', 'B'], columns=['C'])
# C bar foo
# A B
# one A 0.516837 -0.268332
# B 0.005996 -1.168934
# C 0.083572 0.166766
# three A 1.339747 NaN
# B NaN -0.210904
# C -0.848954 NaN
# two A NaN 1.172619
# B -0.667602 NaN
# C NaN 1.245084
9. 시계열 데이터 (Time Series)
판다스는 시계열 데이터를 주기를 변경하거나 샘플링하는데 간단하고 강력한 기능을 제공합니다. 또한 금융 데이터를 다루기에도 편리합니다. (예를 들어 1초마다 쌓은 데이터를 5분 단위로 변경하고 싶을 때)
이 장에 대해 자세한 설명은 Time Series section을
resample()을 이용하여 데이터 샘플링을 할 수 있습니다.
# 1초 단위로 100개의 index 생성
rng = pd.date_range('1/1/2012', periods=100, freq='S')
# 0~500 사이 랜덤값 입력
ts = pd.Series(np.random.randint(0, 500, len(rng)), index=rng)
# 5분 단위로 샘플링하여 sum()
ts.resample('5Min').sum()
# 2012-01-01 23289
# Freq: 5T, dtype: int32
다양한 타임존으로 변경할 수도 있습니다.
rng = pd.date_range('3/6/2012 00:00', periods=5, freq='D')
ts = pd.Series(np.random.randn(len(rng)), rng)
# 2012-03-06 -0.104793
# 2012-03-07 1.151961
# 2012-03-08 0.504693
# 2012-03-09 -0.758065
# 2012-03-10 -0.400617
# Freq: D, dtype: float64
# 표준시(UTC)로 변경
ts_utc = ts.tz_localize('UTC')
# 2012-03-06 00:00:00+00:00 -0.104793
# 2012-03-07 00:00:00+00:00 1.151961
# 2012-03-08 00:00:00+00:00 0.504693
# 2012-03-09 00:00:00+00:00 -0.758065
# 2012-03-10 00:00:00+00:00 -0.400617
# Freq: D, dtype: float64
# US 동부 시각으로 변경
ts_utc.tz_convert('US/Eastern')
# 2012-03-05 19:00:00-05:00 -0.104793
# 2012-03-06 19:00:00-05:00 1.151961
# 2012-03-07 19:00:00-05:00 0.504693
# 2012-03-08 19:00:00-05:00 -0.758065
# 2012-03-09 19:00:00-05:00 -0.400617
# Freq: D, dtype: float64
시간 간격(TimeSpan)도 쉽게 표현할 수 있습니다.
# 매달('M') 기준으로 생성
rng = pd.date_range('1/1/2012', periods=5, freq='M')
ts = pd.Series(np.random.randn(len(rng)), index=rng)
# 2012-01-31 -0.087643
# 2012-02-29 1.782097
# 2012-03-31 -0.485397
# 2012-04-30 2.536808
# 2012-05-31 3.062771
# Freq: M, dtype: float64
ps = ts.to_period()
# 2012-01 -0.087643
# 2012-02 1.782097
# 2012-03 -0.485397
# 2012-04 2.536808
# 2012-05 3.062771
# Freq: M, dtype: float64
ps.to_timestamp()
# 2012-01-01 -0.087643
# 2012-02-01 1.782097
# 2012-03-01 -0.485397
# 2012-04-01 2.536808
# 2012-05-01 3.062771
# Freq: MS, dtype: float64
기간(period)과 시간(timestamp) 사이에 산술적인 기능들을 적용할 수 있습니다. 아래 예제에서는 분기별로 9시간을 더한 시각을 기준으로 볼 수 있습니다.
# 분기 단위로 시간 인덱스를 생성합니다.
prng = pd.period_range('1990Q1', '2000Q4', freq='Q-NOV')
ts = pd.Series(np.random.randn(len(prng)), prng)
ts.index = (prng.asfreq('M', 'e') + 1).asfreq('H', 's') + 9
ts.head()
# 1990-03-01 09:00 1.318669
# 1990-06-01 09:00 -0.094259
# 1990-09-01 09:00 0.076941
# 1990-12-01 09:00 -0.216037
# 1991-03-01 09:00 0.203854
# Freq: H, dtype: float64
10. 범주형 데이터 (Categoricals)
DataFrame 안에는 범주형 데이터도 넣을 수 있습니다.
이 장에 대해 자세한 설명은 categorical introduction와 API documentation을 참고하세요.
.astype("category")로 범주형 데이터 타입으로 변환할 수 있습니다.
df = pd.DataFrame({"id":[1,2,3,4,5,6], "raw_grade":['a', 'b', 'b', 'a', 'a', 'e']})
# category형 데이터 타입으로 변환합니다.
df["grade"] = df["raw_grade"].astype("category")
df["grade"]
# 0 a
# 1 b
# 2 b
# 3 a
# 4 a
# 5 e
# Name: grade, dtype: category
# Categories (3, object): [a, b, e]
cat.categories 속성을 이용하여 카테고리명을 다시 만들 수 있습니다.
df["grade"].cat.categories = ["very good", "good", "very bad"]
cat.set_categories()를 이용하여 카테고리를 재정의할 수 있습니다. 재정의는 현재 갖고 있지 않은 범주도 추가할 수 있습니다.
df["grade"] = df["grade"].cat.set_categories(["very bad", "bad", "medium", "good", "very good"])
# 0 very good
# 1 good
# 2 good
# 3 very good
# 4 very good
# 5 very bad
# Name: grade, dtype: category
# Categories (5, object): [very bad, bad, medium, good, very good]
범주형 데이터를 정렬할 수도 있습니다. 정렬 기준은 문자 기준이 아닌 범주형 자료를 정의할 때 만든 순서로 정렬됩니다.
df.sort_values(by="grade")
# id raw_grade grade
# 5 6 e very bad
# 1 2 b good
# 2 3 b good
# 0 1 a very good
# 3 4 a very good
# 4 5 a very good
범주형 데이터 기준으로 그룹화하여 빈도수를 출력하면, 비어있는 범주도 쉽게 확인할 수 있습니다.
df.groupby("grade").size()
# grade
# very bad 1
# bad 0
# medium 0
# good 2
# very good 3
# dtype: int64
11. 그래프 시각화 (Plotting)
이 장에 대해 자세한 설명은 Plotting을 참고하세요.
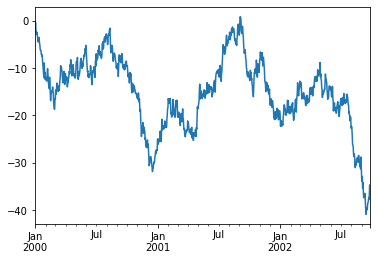
데이터 시각화는 matplotlib API를 사용합니다.
# 랜덤 값으로 1000개의 행을 생성합니다.
ts = pd.Series(np.random.randn(1000), index=pd.date_range('1/1/2000', periods=1000))
# 누적합을 구합니다.
ts = ts.cumsum()
# 시각화합니다.
ts.plot()
DataFrame에서 plot()은 모든 컬럼을 한번에 보여주는 편리함도 있습니다.
df = pd.DataFrame(np.random.randn(1000, 4), index=ts.index,
columns=['A', 'B', 'C', 'D'])
df = df.cumsum()
plt.figure()
df.plot()
plt.legend(loc='best')
12. 파일 입출력 (Getting Data In/Out)
DataFrame을 파일로 생성하거나 파일을 DataFrame으로 읽는 방법입니다.
CSV
이 장에 대해 자세한 설명은 Writing to a csv file, Reading from a csv file을 참고하세요.
.to_csv()로 DataFrame을 쉽게 csv 파일로 쓸 수 있습니다.
df.to_csv('foo.csv')
pd.read_csv()로 csv파일을 DataFrame으로 읽어올 수 있습니다.
pd.read_csv('foo.csv')
# Unnamed: 0 A B C D
# 0 2000-01-01 0.361164 0.270283 -0.567327 -1.045564
# 1 2000-01-02 -0.119395 0.735437 0.147388 -2.754982
# 2 2000-01-03 -1.377198 1.322276 -0.017347 -2.766424
# 3 2000-01-04 -3.120668 0.889602 -0.556911 -3.888872
# 4 2000-01-05 -4.623147 -0.345874 -2.273104 -3.428089
# .. ... ... ... ... ...
# 995 2002-09-22 -12.719088 18.244644 -6.609060 -41.127125
# 996 2002-09-23 -14.052744 18.481692 -7.872954 -41.302499
# 997 2002-09-24 -15.924737 17.051347 -7.630588 -43.195306
# 998 2002-09-25 -15.504673 16.281666 -7.241048 -43.058862
# 999 2002-09-26 -15.336585 16.601851 -9.285505 -44.013105
# [1000 rows x 5 columns]
HDF5
이 장에 대해 자세한 설명은 HDFStores을 참고하세요.
to_hdf()로 HDF5 형식으로 쓸 수 있습니다.
df.to_hdf('foo.h5','df')
pd.read_hdf()로 hdf5 형식을 DataFrame으로 읽어올 수 있습니다.
pd.read_hdf('foo.h5','df')
# A B C D
# 2000-01-01 0.361164 0.270283 -0.567327 -1.045564
# 2000-01-02 -0.119395 0.735437 0.147388 -2.754982
# 2000-01-03 -1.377198 1.322276 -0.017347 -2.766424
# 2000-01-04 -3.120668 0.889602 -0.556911 -3.888872
# 2000-01-05 -4.623147 -0.345874 -2.273104 -3.428089
# ... ... ... ... ...
# 2002-09-22 -12.719088 18.244644 -6.609060 -41.127125
# 2002-09-23 -14.052744 18.481692 -7.872954 -41.302499
# 2002-09-24 -15.924737 17.051347 -7.630588 -43.195306
# 2002-09-25 -15.504673 16.281666 -7.241048 -43.058862
# 2002-09-26 -15.336585 16.601851 -9.285505 -44.013105
# [1000 rows x 4 columns]
Excel
이 장에 대해 자세한 설명은 MS Excel을 참고하세요.
to_excel()로 xlsx 파일 형식으로 쓸 수 있습니다.
df.to_excel('foo.xlsx', sheet_name='Sheet1')
pd.read_excel()로 xlsx 파일로부터 DataFrame으로 읽어올 수 있습니다.
pd.read_excel('foo.xlsx', 'Sheet1', index_col=None, na_values=['NA'])
# Unnamed: 0 A B C D
# 0 2000-01-01 0.361164 0.270283 -0.567327 -1.045564
# 1 2000-01-02 -0.119395 0.735437 0.147388 -2.754982
# 2 2000-01-03 -1.377198 1.322276 -0.017347 -2.766424
# 3 2000-01-04 -3.120668 0.889602 -0.556911 -3.888872
# 4 2000-01-05 -4.623147 -0.345874 -2.273104 -3.428089
# .. ... ... ... ... ...
# 995 2002-09-22 -12.719088 18.244644 -6.609060 -41.127125
# 996 2002-09-23 -14.052744 18.481692 -7.872954 -41.302499
# 997 2002-09-24 -15.924737 17.051347 -7.630588 -43.195306
# 998 2002-09-25 -15.504673 16.281666 -7.241048 -43.058862
# 999 2002-09-26 -15.336585 16.601851 -9.285505 -44.013105
# [1000 rows x 5 columns]
이 포스팅에서 사용한 코드는 이곳에 공개되어 있으며 다운로드 받으실 수 있습니다.